Ve druhém článku o zajímavém a potenciálně užitečném projektu Jython si ukážeme, jakým způsobem je možné v Jythonu používat rozhraní a třídy naimportované ze standardní knihovny jazyka Java. Uvidíme, že – což možná zní poněkud paradoxně – může být použití javovských knihoven snazší a jednodušší v Jythonu než v samotném programovacím jazyku Java.
Obsah
1. Použití standardní knihovny Javy v Jythonu
2. Základní způsoby využití tříd a rozhraní naprogramovaných v Javě z Jythonu
3. Zjednodušené volání getterů a setterů
4. Gettery vracející pravdivostní hodnoty true/false
5. Zkrácený zápis setterů a getterů – praktičtější příklady
6. Komplikace v případě, že jméno getteru/setteru koliduje se jménem atributu
7. Další série benchmarků pro porovnání rychlosti Jythonu, Pythonu 2.x a Pythonu 3.x
8. Výsledky benchmarku z předchozího článku
9. Třetí benchmark – intenzivní konkatenace (spojování) řetězců
10. Skripty pro spuštění benchmarku se zvoleným interpretrem a parametry
11. Výsledky běhu třetího benchmarku
12. „Skryté“ vytváření objektů v benchmarku s řetězci
13. Čtvrtý benchmark – Eratosthenovo síto
14. Skripty pro spuštění benchmarku se zvoleným interpretrem a parametry
15. Výsledky běhu čtvrtého benchmarku
16. Pád benchmarku v případě Jythonu
17. Jednoduchá GUI aplikace naprogramovaná v Jythonu
18. Nepatrně složitější příklad – dvě tlačítka na GUI
19. Repositář s demonstračními příklady
1. Použití standardní knihovny Javy v Jythonu
V prvním článku o Jythonu jsme se seznámili s programovacími jazyky vytvořenými pro běh (spouštění) v nich vytvořených aplikací nad virtuálním strojem jazyka Javy (JVM – Java Virtual Machine). Připomeňme si, že se jedná například o jazyky Scala, Clojure, Groovy, Ruby (JRuby), Python (Jython) a v neposlední řadě taktéž JavaScript (implementované ve dvou projektech Rhino a Nashorn) i relativně nový jazyk Kotlin. Taktéž jsme si ukázali postup při instalaci Jythonu, spuštění interaktivní smyčky REPL, popsali jsme si základní knihovny dodávané společně s Jythonem a na závěr byly uvedeny dva benchmarky měřící rychlost provádění výpočtů s datovými typy float a complex.
Jazyky pro JVM zmíněné minule:
| Jazyk pro JVM | Stručný popis | Odkaz |
|---|---|---|
| Java | primární jazyk pro JVM, bajtkód odpovídá právě Javě | https://www.oracle.com/java/index.html |
| Clojure | moderní dialekt programovacího jazyka Lisp | https://clojure.org/ |
| Groovy | dynamicky typovaný jazyk pro JVM | http://groovy-lang.org/ |
| Rhino | jedna z implementací JavaScriptu | https://developer.mozilla.org/en-US/docs/Mozilla/Projects/Rhino |
| Nashorn | alternativní implementace JavaScriptu | https://blogs.oracle.com/nashorn/ |
| JRuby | portace jazyka Ruby na JVM | http://jruby.org/ |
| Jython | portace jazyka Python na JVM | http://www.jython.org/ |
| Kotlin | moderní staticky typovaný jazyk | http://kotlinlang.org/ |
| Scala | další moderní jazyk pro JVM | https://www.scala-lang.org/ |

Obrázek 1: Logo programovacího jazyka Jython, jehož popisu je dnešní článek věnován.
Dnes si řekneme, jakým způsobem je možné ve skriptech psaných v Jythonu používat rozhraní (interface) a třídy (class) nabízené základní knihovnou programovacího jazyka Java, která je dnes již velmi rozsáhlá (odkaz vede na knihovnu určenou pro JDK verze 1.9, ovšem podobně rozsáhlá byla již pro verze 1.5-1.8). Zajímavý a na první pohled možná poněkud paradoxní je fakt, že použití standardní knihovny Javy (a vlastně i mnoha dalších javovských knihoven) je v případě volání těchto knihoven z Jythonu mnohem jednodušší, než je tomu ve vlastním jazyku Java. To ostatně uvidíme i na dále popsaných demonstračních příkladech, jejichž verze psané v Jythonu jsou v naprosté většině případů kratší a přehlednější, než varianty vyvinuté přímo v programovacím jazyku Java. Jython je v tomto ohledu porovnatelný především s programovacím jazykem Groovy a v obecnějším pohledu i se Scalou a Kotlinem (i když typový systém těchto jazyků je odlišný).
2. Základní způsoby využití tříd a rozhraní naprogramovaných v Javě z Jythonu
Již v předchozím článku jsme se seznámili se základními způsoby komunikace mezi skripty psanými v programovacím jazyku Jython a třídami popř. rozhraními vytvořenými v Javě (včetně již zmíněné a rozsáhlé standardní knihovny Javy). Připomeňme si ve stručnosti, jak vlastně vypadá konstrukce objektu daného typu (třídy). V programovacím jazyku Java vypadá programový kód pro vytvoření nového objektu přibližně takto. Uvádíme si příklad na všeobecně známé implementaci seznamů představované třídou ArrayList implementující rozhraní List:
List l = new ArrayList();
Naproti tomu v případě Jythonu je situace poněkud jednodušší a především přehlednější, a to díky jeho dynamickému typovému systému. V praxi to znamená, že se nikde neuvádí typ proměnné, do které se přiřazuje právě vytvořená instance třídy. Navíc není nutné explicitně zapisovat operátor new, protože volání konstruktoru vypadá v Pythonu odlišně – zapisuje se podobně jako volání funkce, ovšem namísto jména funkce se použije jméno třídy (popř. rozhraní):
l = ArrayList()
Poznámka: třídu ArrayList je samozřejmě nutné nejdříve do skriptu naimportovat, což se provádí příkazem import třída nebo jeho variantou from balíček import třída:
from java.util import ArrayList
Typ objektu, resp. přesněji řečeno typ hodnoty, je uložen společně s objektem/hodnotou referencovanou v proměnné l. Můžeme se o tom snadno přesvědčit (například přímo v interaktivní smyčce Jythonu):
$ type(l) <type 'java.util.ArrayList'>
Ve chvíli, kdy je instance třídy (tj. objekt) vytvořen, můžeme volat jeho metody popř. přistupovat k jeho atributům. Opět si to ukažme na velmi jednoduchém příkladu, v němž budeme volat dvě metody objektu typu ArrayList:
>>> l.append(1) >>> l.size() 1
3. Zjednodušené volání getterů a setterů
Možnosti programovacího jazyka Jython jdou ovšem ještě dále, než je pouhá konstrukce objektů, volání jejich metod a přístup k atributům objektů. Pokud totiž třída obsahuje gettery a settery, tj. metody určené pro zjištění stavu popř. pro změnu stavu objektu, je možné gettery a settery volat nepřímo – přístupem (čtením či zápisem) do „kvaziatributu“, jehož jméno je odvozeno ze jména příslušného getteru a setteru. Ukažme si to opět na příkladu. Mějme třídu nazvanou CLS s getterem pojmenovaným getValue a setterem pojmenovaným setValue (pojmenování musíme zachovat, protože v Javě se gettery a settery identifikují právě svým jménem). Zdrojový kód této třídy naleznete na adrese https://github.com/tisnik/jython-examples/blob/master/CLS.java:
public class CLS {
int v;
public void setValue(int value) {
this.v = value;
}
public int getValue() {
return this.v;
}
}
Ve chvíli, kdy si v Jythonu vytvoříme instanci této třídy, například do proměnné c, můžeme samozřejmě přímo volat getter a setter, a to prakticky stejně, jako v samotné Javě. Vše si ověříme v interaktivní smyčce REPL:
$ java -jar jython-standalone-2.7.0.jar Jython 2.7.0 (default:9987c746f838, Apr 29 2015, 02:25:11) [OpenJDK 64-Bit Server VM (Oracle Corporation)] on java1.7.0_79 Type "help", "copyright", "credits" or "license" for more information. >>> import CLS >>> c = CLS() >>> c.setValue(42) >>> c.getValue() 42
Popř. můžeme – což již v Javě nelze – použít zkráceného zápisu, v němž se namísto explicitního volání getterů a setterů čte či zapisuje kvaziatribut, jehož jméno je odvozeno od názvů getterů a setterů. Opět si ukažme příklad:
>>> c.value 42 >>> c.value=6502 >>> c.value 6502
Podobně je možné při práci s instancí třídy File použít setter nazvaný setExecutable(), který nastavuje bit „executable“:
>>> f2 = File("test")
>>> f2.createNewFile()
True
>>> f2.setExecutable(True)
True
Namísto setteru ovšem můžeme měnit hodnotu pseudoatributu executable, což je kratší a čitelnější:
>>> f3 = File("test2")
>>> f3.createNewFile()
True
>>> f3.executable=True
True
Výsledek si můžete ověřit přímo v souborovém systému.
4. Gettery vracející pravdivostní hodnoty true/false
Některé gettery, které vracejí pravdivostní hodnoty typu Boolean (objektový typ) nebo boolean (primitivní typ), většinou nebývají pojmenovány stylem getJménoAtributu ale spíše isJménoAtributu. V programovacím jazyku Jython však i s těmito gettery můžeme pracovat pořád stejně, tj. můžeme je buď volat explicitně jako jakoukoli jinou metodu nebo přečíst jejich hodnotu s využitím operátoru přiřazení.
Opět si tuto vlastnost ukážeme na jednoduchém demonstračním příkladu. Vytvoříme si instanci třídy File:
>>> from java.io import File
>>> f1=File(".")
Explicitní přístup ke getteru zjišťujícího informace o tom, zda instance třídy File reprezentuje soubor popř. zda reprezentuje adresář, vypadá naprosto stejně jako v Javě:
>>> f1.isFile() False >>> f1.isDirectory() True
Alternativně ovšem můžeme ke stejným getterům přistupovat tak, jakoby se jednalo o běžné (čitelné) atributy:
>>> f1.file False >>> f1.directory True
Ve skutečnosti se samozřejmě o běžné atributy nejedná, o čemž se můžeme snadno přesvědčit pokusem o zápis do nich:
>>> f1.file=False Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: read-only attr: file
5. Zkrácený zápis setterů a getterů – praktičtější příklady
Samozřejmě nezapomeneme ani na praktičtější příklady, které souvisí s použitím setterů a getterů. Nejprve si vyzkoušíme použití getterů deklarovaných ve třídě java.awt.Color, která nese informace o barvě reprezentované v barvovém prostoru RGB. Nejprve vytvoříme instanci této třídy:
from java.awt import Color
c = Color(1, 0, 0)
A dále můžeme volat gettery objektu:
print(c.getRed())
print(c.getGreen())
print(c.getBlue())
print(c.getAlpha())
Popř. použít zkrácený zápis:
print(c.red)
print(c.green)
print(c.blue)
print(c.alpha)
Podívejme se na celý výpis tohoto demonstračního příkladu:
from java.awt import Color
print("red")
c = Color(1, 0, 0)
print(c.getRed())
print(c.getGreen())
print(c.getBlue())
print(c.getAlpha())
print("")
print(c.red)
print(c.green)
print(c.blue)
print(c.alpha)
print("\n\nyellow")
c2 = Color.YELLOW
print(c2.red)
print(c2.green)
print(c2.blue)
print(c2.alpha)
Po spuštění by se na standardní výstup měly vypsat tyto údaje:
red 1 0 0 255 1 0 0 255 yellow 255 255 0 255
Druhý příklad je kratší a ukazuje dvě možnosti, jak napsat test, jestli je nějaká kolekce prázdná či nikoli:
from java.util import ArrayList a = ArrayList() print(a.isEmpty()) print(a.empty)
6. Komplikace v případě, že jméno getteru/setteru koliduje se jménem atributu
Ovšem ne vždy je situace se settery a ještě více s gettery tak snadná jako tomu bylo v předchozích demonstračních příkladech. Může totiž dojít k situaci, kdy nějaká třída obsahuje getter/setter a současně i viditelný atribut (nebo metodu!) stejného jména. V takovém případě dojde k problémům (kvůli nejednoznačnosti), které si můžeme ukázat na dalším demonstračním příkladu:
from java.lang import StringBuffer
s = StringBuffer("Hello world!")
print(s.length())
print(s)
print("")
s.setLength(11)
print(s.length())
print(s)
print("")
s.length = 5
print(s.length())
print(s)
print("")
Výsledek po spuštění:
$ java -jar jython-standalone-2.7.0.jar set_length.py
12
Hello world!
11
Hello world
Traceback (most recent call last):
File "set_length.py", line 15, in <module>
s.length = 5
TypeError: readonly attribute
Proč tomu tak je? Problém spočívá v tom, že třída StringBuffer obsahuje metody setLength() a length(), což do jisté míry porušuje konvence java beans. Proto je přiřazení s.length = 5 nejednoznačné a je nutné použít explicitní volání setteru.
7. Další série benchmarků pro porovnání rychlosti Jythonu, Pythonu 2.x a Pythonu 3.x
Ve druhé části dnešního článku si opět ukážeme několik benchmarků, protože téma efektivity či (nutno přiznat) většinou spíše neefektivity Jythonu v porovnání s dalšími programovacími jazyky, resp. přesněji řečeno s dalšími interpretry Pythonu, se neustále diskutuje a rychlost popř. pomalost Jythonu může vést k tomu, že se tento interpret nebude moci pro konkrétní typ aplikace použít (pomalost Jythonu je jen jednou z nevýhod tohoto jazyka; další nevýhodou je, že Jython je založený na Pythonu 2 a nikoli Pythonu 3). Je tedy vhodné vědět již před zahájením práce na nové aplikaci, jestli bude Jython přínosem či zda naopak bude aplikace nepřiměřeně pomalá nebo náročná na systémové prostředky. Nejprve si připomeneme, k jakým výsledkům jsme došli minule a posléze si ukážeme dva benchmarky zaměřené na práci s řetězci a na použití generátorů a zpracování seznamů.
8. Výsledky benchmarku z předchozího článku
Jen v rychlosti si připomeňme, že minule jsme si ukázali dva benchmarky, které byly zaměřeny především na rychlost výpočtů s hodnotami typu float a complex. Výsledky prvního benchmarku (výpočtu Mandelbrotovy množiny s uložením výsledného rastrového obrázku do souboru typu PPM) vypadají následovně. Měření samozřejmě probíhalo na totožném počítači:
| # | x-res | y-res | Jython (s) | Python 2 (s) | Python 3 (s) |
|---|---|---|---|---|---|
| 1 | 16 | 16 | 1.79 | 0.01 | 0.02 |
| 2 | 24 | 24 | 1.79 | 0.01 | 0.02 |
| 3 | 32 | 32 | 1.84 | 0.02 | 0.02 |
| 4 | 48 | 48 | 2.11 | 0.03 | 0.03 |
| 5 | 64 | 64 | 2.01 | 0.04 | 0.05 |
| 6 | 96 | 96 | 2.16 | 0.08 | 0.09 |
| 7 | 128 | 128 | 2.24 | 0.15 | 0.15 |
| 8 | 192 | 192 | 2.43 | 0.32 | 0.33 |
| 9 | 256 | 256 | 2.81 | 0.57 | 0.58 |
| 10 | 384 | 384 | 3.87 | 1.25 | 1.29 |
| 11 | 512 | 512 | 5.05 | 2.27 | 2.28 |
| 12 | 768 | 768 | 8.61 | 5.07 | 5.21 |
| 13 | 1024 | 1024 | 13.22 | 9.00 | 9.10 |
| 14 | 1536 | 1536 | 28.15 | 20.73 | 21.24 |
| 15 | 2048 | 2048 | 50.03 | 36.11 | 38.24 |
| 16 | 3072 | 3072 | 100.78 | 81.93 | 84.02 |
| 17 | 4096 | 4096 | 179.21 | 144.45 | 148.44 |
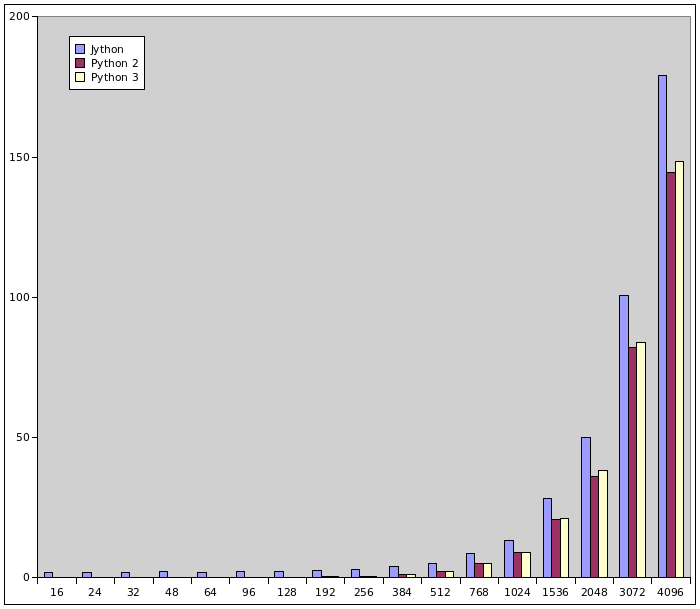
Obrázek 1: Výsledky prvního benchmarku prezentovaného v předchozím článku (výpočet Mandelbrotovy množiny) vynesené do grafu.
Z výsledků druhého benchmarku, který taktéž provádí výpočet Mandelbrotovy množiny, ovšem s datovým typem complex (ten v Javě jako primitivní datový typ neexistuje), je patrné, že je Jython při práci s komplexními čísly výrazně pomalejší než nativní CPython 2.x i CPython 3.x:
| # | x-res | y-res | Jython (s) | Python 2 (s) | Python 3 (s) |
|---|---|---|---|---|---|
| 1 | 16 | 16 | 1.77 | 0.01 | 0.02 |
| 2 | 24 | 24 | 1.99 | 0.01 | 0.02 |
| 3 | 32 | 32 | 1.80 | 0.02 | 0.03 |
| 4 | 48 | 48 | 1.90 | 0.03 | 0.04 |
| 5 | 64 | 64 | 1.99 | 0.04 | 0.06 |
| 6 | 96 | 96 | 2.20 | 0.08 | 0.11 |
| 7 | 128 | 128 | 2.70 | 0.14 | 0.18 |
| 8 | 192 | 192 | 3.15 | 0.32 | 0.43 |
| 9 | 256 | 256 | 4.13 | 0.56 | 0.77 |
| 10 | 384 | 384 | 6.61 | 1.25 | 1.60 |
| 11 | 512 | 512 | 10.10 | 2.22 | 2.71 |
| 12 | 768 | 768 | 20.59 | 5.12 | 6.37 |
| 13 | 1024 | 1024 | 34.45 | 9.09 | 10.78 |
| 14 | 1536 | 1536 | 77.73 | 20.33 | 24.25 |
| 15 | 2048 | 2048 | 134.13 | 35.95 | 43.61 |
| 16 | 3072 | 3072 | 294.04 | 81.64 | 99.77 |
| 17 | 4096 | 4096 | 523.57 | 148.13 | 176.97 |
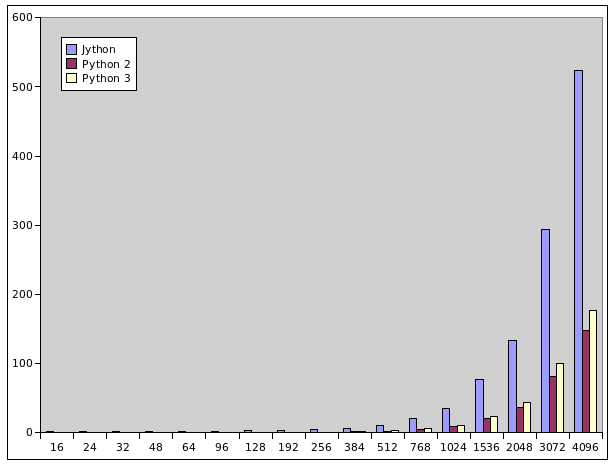
Obrázek 2: Výsledky druhého benchmarku (výpočet Mandelbrotovy množiny s použitím datového typu complex) vynesené do grafu.
První poučení tedy zní – pokud použijeme Jython, je vhodné si dát pozor na to, jak jsou zpracovávány hodnoty typu complex a zda se nebude jednat o úzké hrdlo programu.
9. Třetí benchmark – intenzivní konkatenace (spojování) řetězců
Ve skutečnosti však mnoho v současnosti provozovaných aplikací neprovádí intenzivní výpočty s numerickými hodnotami, ale většina strojového času se stráví prováděním zcela odlišných operací. Typicky se zpracovávají řetězce popř. se intenzivně pracuje s kolekcemi (v Pythonu typicky se seznamy, slovníky a množinami). Nesmíme zapomenout ani na serializaci a deserializaci dat (JSON, XML) tak typické pro webové služby, aplikace s grafickým uživatelským rozhraním či na přístup k databázím. Pojďme si tedy ukázat další dva odlišně pojaté benchmarky. Ve skutečnosti se jedná o takzvané „mikrobenchmarky“ zaměřené pouze na jedinou operaci, což je samozřejmě odlišné od reálných aplikací, ovšem pro základní porovnání mohou být i mikrobenchmarky použitelné (a to zejména ve chvíli, kdy naměřené hodnoty budou výrazně odlišné).
V pořadí již třetí benchmark je po implementační stránce skutečně velmi jednoduchý. Je v něm totiž deklarována funkce, které se předá celé kladné číslo n a výsledkem je řetězec obsahující znaky „0 1 2 ... n“. Tento benchmark tedy – alespoň teoreticky – zkoumá rychlost provádění tří operací:
- Převod celého čísla na řetězec (provedeno celkem n-krát)
- Spojení (konkatenace) dvou řetězců (s kopií znaků druhého řetězce do řetězce prvního, opět provedeno n-krát)
- Činnost automatického správce paměti (garbage collector)
Pro větší hodnoty n bude s velkou pravděpodobností hrát větší roli rychlost konkatenace řetězců, takže si počkejme na výsledky, zda toto očekávání potvrdí.
Následuje výpis celého zdrojového kódu tohoto mikrobenchmarku. Testovanou funkcí bude perform_benchmark():
#!/usr/bin/env python
# vim: set fileencoding=utf-8
from sys import argv, exit
def perform_benchmark(repeat_count):
s = ""
for i in range(1, 1 + repeat_count):
s += str(i) + " "
print(len(s))
return s
if __name__ == "__main__":
if len(argv) < 2:
print("usage: python string_concat repeat_count")
exit(1)
repeat_count = int(argv[1])
perform_benchmark(repeat_count)
10. Skripty pro spuštění benchmarku se zvoleným interpretrem a parametry
Pro spuštění benchmarku použijeme trojici prakticky shodných skriptů, které budou postupně zvětšovat počet čísel (resp. řetězcové podoby těchto čísel) připojovaných k řetězci. Oproti benchmarkům uvedeným minule se vždy počet zvýší na dvojnásobek předchozí hodnoty. Pro malý počet iterací se tedy bude spíše měřit rychlost nastartování interpretru Pythonu (verze 2 či 3) popř. virtuálního stroje Javy a inicializace Jythonu, ovšem u vyšších hodnot již začne převládat rychlost manipulace s řetězci, vliv činnosti správce paměti apod.
Skript pro Jython
Tento skript vyžaduje, aby se v aktuálním adresáři nacházel Java archiv s Jythonem popř. jen symbolický link na tento archiv (jython-standalone-2.7.0.jar):
repeat_count=1
limit=10000000
OUTFILE="jython.times"
PREFIX="jython"
rm -f $OUTFILE
rm -f ${PREFIX}.txt
while [ $repeat_count -lt $limit ]
do
echo $repeat_count
echo -n "$repeat_count " >> $OUTFILE
/usr/bin/time --output $OUTFILE --append --format "%e %M" java -jar jython-standalone-2.7.0.jar string_concat.py $repeat_count >> "${PREFIX}.txt"
repeat_count=$(( $repeat_count * 2 ))
done
Povšimněte si, jakým způsobem se postupně zvyšuje počet iterací.
Skript pro Python 2.x
Skript určený pro klasický interpret Pythonu 2 vypadá následovně:
repeat_count=1
limit=10000000
OUTFILE="python2.times"
PREFIX="python2"
rm -f $OUTFILE
rm -f ${PREFIX}.txt
while [ $repeat_count -lt $limit ]
do
echo $repeat_count
echo -n "$repeat_count " >> $OUTFILE
/usr/bin/time --output $OUTFILE --append --format "%e %M" python2 -B string_concat.py $repeat_count >> "${PREFIX}.txt"
repeat_count=$(( $repeat_count * 2 ))
done
Skript pro Python 3.x
Skript pro interpret Pythonu 3 se prakticky neliší od předchozího skriptu, což je ovšem pochopitelné:
repeat_count=1
limit=10000000
OUTFILE="python3.times"
PREFIX="python3"
rm -f $OUTFILE
rm -f ${PREFIX}.txt
while [ $repeat_count -lt $limit ]
do
echo $repeat_count
echo -n "$repeat_count " >> $OUTFILE
/usr/bin/time --output $OUTFILE --append --format "%e %M" python3 -B string_concat.py $repeat_count >> "${PREFIX}.txt"
repeat_count=$(( $repeat_count * 2 ))
done
11. Výsledky běhu třetího benchmarku
Výsledky získané po spuštění třetího benchmarku s využitím Jythonu, interpretru Pythonu 2 a interpretru Pythonu 3 jsou ukázány na grafu a taktéž vypsány v následující tabulce.
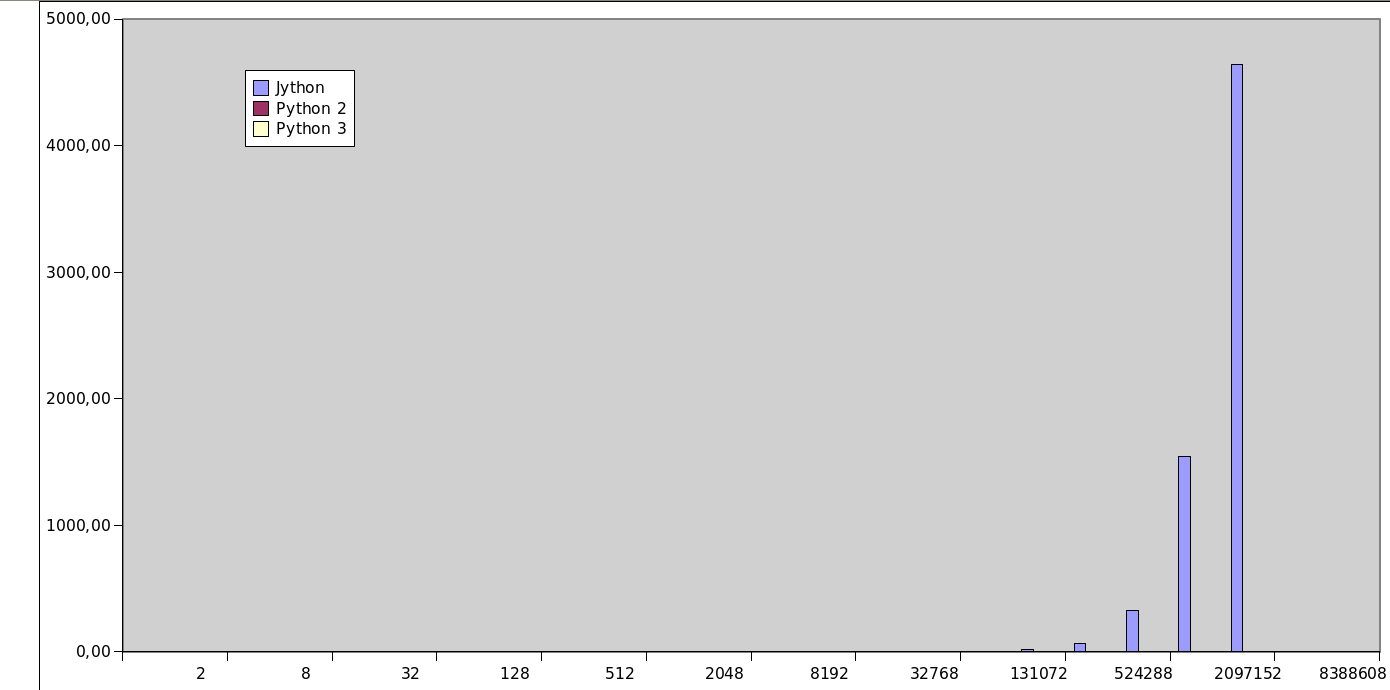
Obrázek 3: Výsledky třetího benchmarku (konkatenace řetězců) vynesené do grafu. Časy Jythonu jsou tak vysoké, že časy běhu Pythonu 2 a Pythonu 3 nejsou viditelné.
Zde prakticky není důvod pro další zkoumání naměřených hodnot, protože Jython je zde evidentně mnohem pomalejší.
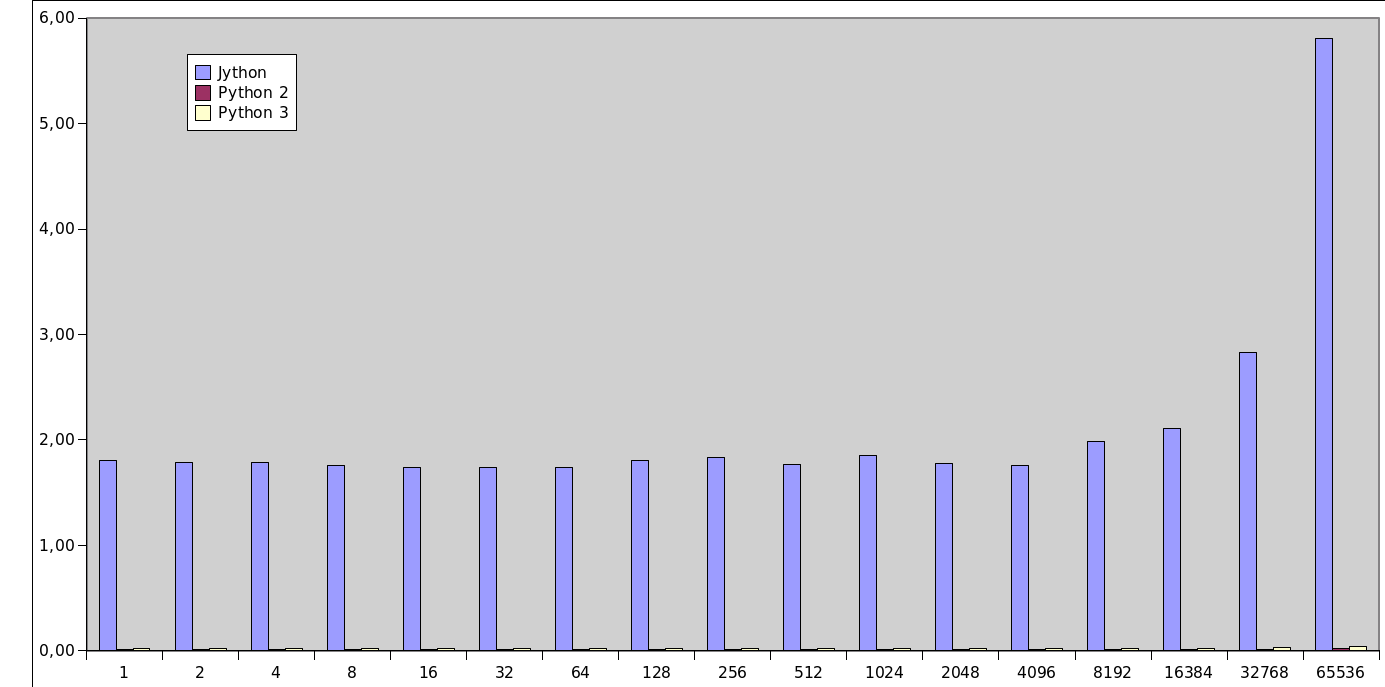
Obrázek 4: Výsledky třetího benchmarku bez několika posledních iterací.
Všechny časy jsou uvedeny v sekundách a pokud je namísto času zapsán znak ×, znamená to pád benchmarku vysvětlený níže:
| # | iter | Jython (s) | Python 2 (s) | Python 3 (s) |
|---|---|---|---|---|
| 1 | 1 | 1.81 | 0.01 | 0.02 |
| 2 | 2 | 1.79 | 0.01 | 0.02 |
| 3 | 4 | 1.79 | 0.01 | 0.02 |
| 4 | 8 | 1.76 | 0.01 | 0.02 |
| 5 | 16 | 1.74 | 0.01 | 0.02 |
| 6 | 32 | 1.74 | 0.01 | 0.02 |
| 7 | 64 | 1.74 | 0.01 | 0.02 |
| 8 | 128 | 1.81 | 0.01 | 0.02 |
| 9 | 256 | 1.83 | 0.01 | 0.02 |
| 10 | 512 | 1.77 | 0.01 | 0.02 |
| 11 | 1024 | 1.85 | 0.01 | 0.02 |
| 12 | 2048 | 1.78 | 0.01 | 0.02 |
| 13 | 4096 | 1.76 | 0.01 | 0.02 |
| 14 | 8192 | 1.99 | 0.01 | 0.02 |
| 15 | 16384 | 2.11 | 0.01 | 0.02 |
| 16 | 32768 | 2.83 | 0.01 | 0.03 |
| 17 | 65536 | 5.81 | 0.02 | 0.04 |
| 18 | 131072 | 16.96 | 0.04 | 0.05 |
| 19 | 262144 | 68.53 | 0.06 | 0.09 |
| 20 | 524288 | 326.14 | 0.12 | 0.16 |
| 21 | 1048576 | 1546.85 | 0.23 | 0.31 |
| 22 | 2097152 | 4644.08 | 0.44 | 0.62 |
| 23 | 4194304 | × | 0.86 | 1.23 |
| 24 | 8388608 | × | 1.74 | 2.45 |
V tabulce můžeme vidět mnoho zajímavých údajů a trendů. Zejména z porovnání Pythonu 2.x a 3.x vyplývá, že Python 2.x je při práci s řetězci nepatrně rychlejší. Je tomu tak z toho důvodu, že v Pythonu 3.3 a v dalších verzích se s řetězci pracuje odlišně, což je téma, kterému jsem se věnoval na konkurenčním serveru. Zcela odlišné jsou výsledky v případě Jythonu, kde nejprve měříme především rychlost startu JVM, od přibližně 10000 iterací se čas postupně zvyšuje a od určité hranice (cca 200000 iterací) můžeme vidět, že rychlost zpracování klesá a pro největší počet iterací navíc došlo k pádu aplikace kvůli překročení nastaveného limitu alokované paměti pro JVM (!):
Traceback (most recent call last):
File "string_concat.py", line 22, in <module>
perform_benchmark(repeat_count)
File "string_concat.py", line 9, in perform_benchmark
for i in range(1, 1 + repeat_count):
java.lang.OutOfMemoryError: Java heap space
at org.python.core.Py.newInteger(Py.java:596)
at org.python.core.PyInteger.int___add__(PyInteger.java:312)
at org.python.core.PyInteger.__add__(PyInteger.java:299)
at org.python.core.PyObject._basic_add(PyObject.java:2133)
at org.python.core.PyObject._add(PyObject.java:2119)
at org.python.core.__builtin__.range(__builtin__.java:928)
at org.python.core.__builtin__.range(__builtin__.java:903)
at org.python.core.BuiltinFunctions.__call__(__builtin__.java:125)
at org.python.core.PyObject.__call__(PyObject.java:482)
at org.python.pycode._pyx0.perform_benchmark$1(string_concat.py:13)
at org.python.pycode._pyx0.call_function(string_concat.py)
at org.python.core.PyTableCode.call(PyTableCode.java:167)
at org.python.core.PyBaseCode.call(PyBaseCode.java:138)
at org.python.core.PyFunction.__call__(PyFunction.java:413)
at org.python.pycode._pyx0.f$0(string_concat.py:22)
at org.python.pycode._pyx0.call_function(string_concat.py)
at org.python.core.PyTableCode.call(PyTableCode.java:167)
at org.python.core.PyCode.call(PyCode.java:18)
at org.python.core.Py.runCode(Py.java:1386)
at org.python.util.PythonInterpreter.execfile(PythonInterpreter.java:296)
at org.python.util.jython.run(jython.java:362)
at org.python.util.jython.main(jython.java:142)
java.lang.OutOfMemoryError: java.lang.OutOfMemoryError: Java heap space
12. „Skryté“ vytváření objektů v benchmarku s řetězci
Můžeme se ptát, v čem vlastně spočívá pomalost Jythonu při opakovaných konkatenacích řetězců? Na prvním místě si musíme ozřejmit uvědomit, jakým způsobem s řetězci pracuje virtuální stroj Javy, tj. JVM. Bajtkód příslušné funkce po jejím překladu do bajtkódu vypadá přibližně takto:
0: ldc #2; //String 2: astore_0 3: iconst_0 4: istore_1 5: iload_1 6: sipush 10000 9: if_icmpge 42 // na bajtu s indexem 42 je konec smyčky * 12: new #3; //class java/lang/StringBuilder * 15: dup * 16: invokespecial #4; //Method java/lang/StringBuilder."(init)":()V * 19: aload_0 * 20: invokevirtual #5; //Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; * 23: iload_1 * 24: invokevirtual #6; //Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder; * 27: ldc #7; //String * 29: invokevirtual #5; //Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; * 32: invokevirtual #8; //Method java/lang/StringBuilder.toString:()Ljava/lang/String; * 35: astore_0 36: iinc 1, 1 // zvýšení hodnoty počitadla 39: goto 5 // skok zpět na začátek smyčky 42: aload_0 43: areturn
Vzhledem k tomu, že výše uvedený bajtkód je pro velkou část programátorů v Javě či Pythonu poměrně nepřehledný a špatně čitelný, je níže pro ilustraci vypsán programový kód, který je do co největší míry ekvivalentní s instrukcemi, jež se vyskytují ve vygenerovaném bajtkódu. Povšimněte si, že se v tomto zdrojovém kódu instance třídy StringBuilder ihned po svém vytvoření (konstrukci) naplní původním řetězcem, ke kterému se mají připisovat další znaky. Posléze se do tohoto objektu přidá textová reprezentace celého čísla následovaná řetězcem obsahujícím mezeru. Poslední operací, která se s instancí třídy StringBuffer provádí, je převod jejího atributu zpět na řetězec:
String str = "";
for (int i = 0; i < LOOP_COUNT; i++)
{
StringBuilder tmp = new StringBuilder();
tmp.append(str);
tmp.append(i);
tmp.append(" ");
str = tmp.toString();
}
return str;
A právě neustálé vytváření objektů uvnitř programové smyčky a opakované připojování již vytvořeného řetězce do StringBuilderu je velmi náročné jak na paměť, tak i na výkonnost automatického správce paměti. V interpretrech Pythonu je tato činnost evidentně vyřešena mnohem efektivněji
13. Čtvrtý benchmark – Eratosthenovo síto
Čtvrtý a současně i poslední benchmark, s nímž se seznámíme, již nebude zaměřen ani na numerické výpočty ani na masivní práci s řetězci. Bude v něm implementován algoritmus pro nalezení všech prvočísel ve specifikovaném rozsahu. Konkrétně pro zjištění prvočísel použijeme tzv. Eratosthenovo síto, které slouží na zjištění všech hodnot, které NEjsou prvočísly. Zbylé hodnoty pochopitelně prvočísly budou. Tento algoritmus je možné implementovat mnoha různými způsoby. V našem konkrétním benchmarku s výhodou využijeme některé vlastnosti Pythonu: práci s množinami (tam se uloží hodnoty, které NEjsou prvočísly), použití generátorů (yield) a taktéž funkce range, která nám prakticky zadarmo vygeneruje všechny celočíselné násobky určité hodnoty. Zdrojový kód benchmarku vypadá následovně:
#!/usr/bin/env python
# vim: set fileencoding=utf-8
from sys import argv
def sieve(n):
multiples = set()
for i in range(2, n+1):
if i not in multiples:
yield i
multiples.update(range(i*i, n+1, i))
if __name__ == "__main__":
if len(argv) < 2:
print("usage: python sieve_algorithm repeat_count")
exit(1)
max_value = int(argv[1])
primes = list(sieve(max_value))
print(len(primes))
14. Skripty pro spuštění benchmarku se zvoleným interpretrem a parametry
Pro spuštění posledního benchmarku opět použijeme trojici prakticky shodných skriptů, které budou postupně zvětšovat počet generovaných prvočísel. Oproti benchmarkům uvedeným minule se vždy počet zvýší na dvojnásobek předchozí hodnoty. Pro malý počet iterací se tedy bude spíše měřit rychlost nastartování interpretru Pythonu (verze 2 či 3) popř. virtuálního stroje Javy a inicializace Jythonu, ovšem u vyšších hodnot již začne převládat rychlost nebo pomalost vlastního algoritmu.
Skript pro Jython
max_value=1
limit=100000000
OUTFILE="jython.times"
PREFIX="jython"
rm -f $OUTFILE
rm -f ${PREFIX}.txt
while [ $max_value -lt $limit ]
do
echo $max_value
echo -n "$max_value " >> $OUTFILE
/usr/bin/time --output $OUTFILE --append --format "%e %M" java -jar jython-standalone-2.7.0.jar sieve_algorithm.py $max_value >> "${PREFIX}.txt"
max_value=$(( $max_value * 2 ))
done
Skript pro Python 2.x
max_value=1
limit=100000000
OUTFILE="python2.times"
PREFIX="python2"
rm -f $OUTFILE
rm -f ${PREFIX}.txt
while [ $max_value -lt $limit ]
do
echo $max_value
echo -n "$max_value " >> $OUTFILE
/usr/bin/time --output $OUTFILE --append --format "%e %M" python2 -B sieve_algorithm.py $max_value >> "${PREFIX}.txt"
max_value=$(( $max_value * 2 ))
done
Skript pro Python 3.x
max_value=1
limit=100000000
OUTFILE="python3.times"
PREFIX="python3"
rm -f $OUTFILE
rm -f ${PREFIX}.txt
while [ $max_value -lt $limit ]
do
echo $max_value
echo -n "$max_value " >> $OUTFILE
/usr/bin/time --output $OUTFILE --append --format "%e %M" python3 -B sieve_algorithm.py $max_value >> "${PREFIX}.txt"
max_value=$(( $max_value * 2 ))
done
15. Výsledky běhu čtvrtého benchmarku
Podívejme se nyní na výsledky benchmarku, nejprve v grafové podobě. Z výsledků je patrné, že benchmark spuštěný v Jythonu je opět nejpomalejší a navíc se se zvyšujícím se nejvyšším prvočíslem dále zpomaluje (minimálně v porovnání s implementací Pythonu 2 i 3). Zajímavé je, že až na pomalejší start je Python 3 nepatrně rychlejší, než Python 2:

Obrázek 4: Výsledky čtvrtého benchmarku (konkatenace řetězců) vynesené do grafu.
Stejné výsledky, tentokrát zapsané do tabulky:
| # | iter | Jython (s) | Python 2 (s) | Python 3 (s) |
|---|---|---|---|---|
| 1 | 1 | 2.70 | 0.01 | 0.02 |
| 2 | 2 | 2.71 | 0.01 | 0.02 |
| 3 | 4 | 2.60 | 0.01 | 0.02 |
| 4 | 8 | 2.58 | 0.01 | 0.02 |
| 5 | 16 | 2.53 | 0.01 | 0.02 |
| 6 | 32 | 2.04 | 0.01 | 0.02 |
| 7 | 64 | 1.89 | 0.01 | 0.02 |
| 8 | 128 | 1.83 | 0.01 | 0.02 |
| 9 | 256 | 1.93 | 0.01 | 0.02 |
| 10 | 512 | 2.04 | 0.01 | 0.02 |
| 11 | 1024 | 1.92 | 0.01 | 0.02 |
| 12 | 2048 | 1.82 | 0.01 | 0.02 |
| 13 | 4096 | 1.80 | 0.01 | 0.02 |
| 14 | 8192 | 1.87 | 0.01 | 0.02 |
| 15 | 16384 | 1.83 | 0.01 | 0.02 |
| 16 | 32768 | 1.85 | 0.01 | 0.03 |
| 17 | 65536 | 1.82 | 0.02 | 0.03 |
| 18 | 131072 | 1.93 | 0.04 | 0.05 |
| 19 | 262144 | 2.04 | 0.08 | 0.08 |
| 20 | 524288 | 2.29 | 0.18 | 0.17 |
| 21 | 1048576 | 2.99 | 0.41 | 0.35 |
| 22 | 2097152 | 3.95 | 0.88 | 0.73 |
| 23 | 4194304 | 5.64 | 1.86 | 1.44 |
| 24 | 8388608 | 12.99 | 3.96 | 2.88 |
| 25 | 16777216 | 26.61 | 8.20 | 5.95 |
| 26 | 33554432 | 123.79 | 16.80 | 12.29 |
| 27 | 67108864 | 273.94 | 34.88 | 25.75 |
16. Pád benchmarku v případě Jythonu
Jen na okraj – podobně, jako se to stalo v případě benchmarku pro konkatenaci řetězců, můžeme podobným způsobem „narazit“ i u čtvrtého benchmarku, v němž poměrně brzy dojde k pádu aplikace kvůli problémům s alokací paměti. Opět to souvisí s odlišným způsobem interní reprezentace objektů v JVM a v interpretrech Pythonu (konkrétně CPythonu):
Traceback (most recent call last):
File "sieve_algorithm.py", line 21, in
primes = list(sieve(max_value))
File "sieve_algorithm.py", line 12, in sieve
multiples.update(range(i*i, n+1, i))
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.concurrent.ConcurrentHashMap.putVal(ConcurrentHashMap.java:1019)
at java.util.concurrent.ConcurrentHashMap.put(ConcurrentHashMap.java:1006)
at java.util.Collections$SetFromMap.add(Collections.java:5461)
at org.python.core.BaseSet._update(BaseSet.java:47)
at org.python.core.BaseSet._update(BaseSet.java:28)
at org.python.core.PySet.set_update(PySet.java:297)
at org.python.core.PySet$set_update_exposer.__call__(Unknown Source)
at org.python.core.PyObject.__call__(PyObject.java:461)
at org.python.core.PyObject.__call__(PyObject.java:465)
at org.python.pycode._pyx0.sieve$1(sieve_algorithm.py:9)
at org.python.pycode._pyx0.call_function(sieve_algorithm.py)
at org.python.core.PyTableCode.call(PyTableCode.java:167)
at org.python.core.PyGenerator.__iternext__(PyGenerator.java:156)
at org.python.core.PyGenerator.__iternext__(PyGenerator.java:138)
at org.python.core.WrappedIterIterator.hasNext(WrappedIterIterator.java:23)
at org.python.core.PyList.list___init__(PyList.java:138)
at org.python.core.PyList$exposed___new__.createOfType(Unknown Source)
at org.python.core.PyOverridableNew.new_impl(PyOverridableNew.java:12)
at org.python.core.PyType.invokeNew(PyType.java:494)
at org.python.core.PyType.type___call__(PyType.java:1706)
at org.python.core.PyType.__call__(PyType.java:1696)
at org.python.core.PyObject.__call__(PyObject.java:461)
at org.python.core.PyObject.__call__(PyObject.java:465)
at org.python.pycode._pyx0.f$0(sieve_algorithm.py:22)
at org.python.pycode._pyx0.call_function(sieve_algorithm.py)
at org.python.core.PyTableCode.call(PyTableCode.java:167)
at org.python.core.PyCode.call(PyCode.java:18)
at org.python.core.Py.runCode(Py.java:1386)
at org.python.util.PythonInterpreter.execfile(PythonInterpreter.java:296)
at org.python.util.jython.run(jython.java:362)
at org.python.util.jython.main(jython.java:142)
java.lang.OutOfMemoryError: java.lang.OutOfMemoryError: GC overhead limit exceeded
17. Jednoduchá GUI aplikace naprogramovaná v Jythonu
V samotném závěru dnešního článku si ukážeme, jak jednoduché je v Jythonu vytvořit aplikaci s grafickým uživatelským rozhraním založeným na knihovně Swing. Oproti kódu naprogramovanému v Javě je skript napsaný v Jythonu velmi krátký, což do značné míry souvisí s dynamickým typovým systémem a taktéž s tím, že v Jythonu jsou funkce plnohodnotným datovým typem, na rozdíl od Javy. To mj. znamená, že je možné běžnou funkci použít jako handler nějaké události, což by se v Javě muselo řešit s využitím anonymní třídy:
button = JButton('Test', actionPerformed=on_button_clicked)
from javax.swing import JButton
from javax.swing import JFrame
frame = JFrame("Simple GUI",
defaultCloseOperation=JFrame.EXIT_ON_CLOSE,
size=(320, 240))
def on_button_clicked(event):
print 'Button clicked!'
button = JButton('Test', actionPerformed=on_button_clicked)
frame.add(button)
frame.visible = True
18. Nepatrně složitější příklad – dvě tlačítka na GUI
Ve druhém podobně laděném příkladu je ukázáno, že handlerem události může být i anonymní funkce, která se v Pythonu vytváří s využitím klíčového slova lambda:
import sys
from javax.swing import JButton
from javax.swing import JFrame
from java.awt import Component, GridLayout
frame = JFrame("Simple GUI",
defaultCloseOperation=JFrame.EXIT_ON_CLOSE,
size=(320, 240))
contentPane = frame.getContentPane()
contentPane.setLayout(GridLayout(2, 1))
def on_button_clicked(event):
print 'Button clicked!'
button1 = JButton('Test', actionPerformed=on_button_clicked)
button2 = JButton('Quit', actionPerformed=lambda event:sys.exit())
frame.add(button1)
frame.add(button2)
frame.visible = True
Složitější ukázky podobným způsobem vytvořených aplikací si ukážeme příště.
19. Repositář s demonstračními příklady
Všechny demonstrační příklady, které jsme si v dnešním článku ukázali, jsou uloženy v repositáři, který naleznete na adrese https://github.com/tisnik/jython-examples. Následují odkazy na jednotlivé příklady (pro jejich spuštění je nutné mít v aktuálním adresáři symbolický link na Java archiv jython-standalone-2.7.0.jar):
| Zdrojový kód/skript | Adresa |
|---|---|
| array_list_is_empty.py | https://github.com/tisnik/jython-examples/blob/master/arraylist_is_empty/array_is_empty.py |
| button_class.py | https://github.com/tisnik/jython-examples/blob/master/attribute_lookup/button_class.py |
| color_class.py | https://github.com/tisnik/jython-examples/blob/master/attribute_lookup/color_class.py |
| string_buffer_class.py | https://github.com/tisnik/jython-examples/blob/master/attribute_lookup/string_buffer_class.py |
| color_getters.py | https://github.com/tisnik/jython-examples/blob/master/ |
| string_buffer_length.py | https://github.com/tisnik/jython-examples/blob/master/ |
| simple_gui.py | https://github.com/tisnik/jython-examples/blob/master/ |
| two_buttons.py | https://github.com/tisnik/jython-examples/blob/master/ |
Dnes popsané benchmarky (v pořadí třetí a čtvrtý) se skládají z většího množství souborů a proto jsou vypsány v samostatných tabulkách:
Třetí benchmark
Čtvrtý benchmark
20. Odkazy na Internetu
- Stránka projektu Jython
http://www.jython.org/ - Jython (Wikipedia)
https://en.wikipedia.org/wiki/Jython - Scripting for the Java Platform (Wikipedia)
https://en.wikipedia.org/wiki/Scripting_for_the_Java_Platform - JSR 223: Scripting for the JavaTM Platform
https://jcp.org/en/jsr/detail?id=223 - List of JVM languages
https://en.wikipedia.org/wiki/List_of_JVM_languages - Stránka programovacího jazyka Java
https://www.oracle.com/java/index.html - Stránka programovacího jazyka Clojure
http://clojure.org - Stránka programovacího jazyka Groovy
http://groovy-lang.org/ - Stránka programovacího jazyka JRuby
http://jruby.org/ - Stránka programovacího jazyka Kotlin
http://kotlinlang.org/ - Stránka programovacího jazyka Scala
https://www.scala-lang.org/ - Projekt Rhino
https://developer.mozilla.org/en-US/docs/Mozilla/Projects/Rhino - Clojure (Wikipedia)
https://en.wikipedia.org/wiki/Clojure - Groovy (Wikipedia)
https://en.wikipedia.org/wiki/Groovy_%28programming_language%29 - JRuby (Wikipedia)
https://en.wikipedia.org/wiki/JRuby - Kotlin (Wikipedia)
https://en.wikipedia.org/wiki/Kotlin_%28programming_language%29 - Scala (Wikipedia)
https://en.wikipedia.org/wiki/Scala_%28programming_language%29 - Python Interpreters Benchmarks
https://pybenchmarks.org/u64q/jython.php - Apache Kafka Producer Benchmarks - Java vs. Jython vs. Python
http://mrafayaleem.com/2016/03/31/apache-kafka-producer-benchmarks/ - What is Jython and is it useful at all? (Stack Overflow)
https://stackoverflow.com/questions/1859865/what-is-jython-and-is-it-useful-at-all - Sieve of Eratosthenes (Wikipedia)
https://en.wikipedia.org/wiki/Sieve_of_Eratosthenes - Sieve of Eratosthenes (Geeks for Geeks)
https://www.geeksforgeeks.org/sieve-of-eratosthenes/ - Sieve of Eratosthenovo (Rosetta code)
http://rosettacode.org/wiki/Sieve_of_Eratosthenes - Monitorování procesů a správa paměti v JDK6 a JDK7 (1)
https://www.root.cz/clanky/monitorovani-procesu-a-sprava-pameti-v-jdk6-a-jdk7-1/ - Monitorování procesů a správa paměti v JDK6 a JDK7 (2)
https://www.root.cz/clanky/monitorovani-procesu-a-sprava-pameti-v-jdk6-a-jdk7-2/
