
Ve druhé části článku o použití assembleru v Linuxu se seznámíme s dalšími jednoduchými příklady, v nichž se budou využívat pouze služby jádra operačního systému, což znamená, že k vytvářeným programům nebude nutné připojovat (linkovat) žádné další knihovny. Všechny příklady budou připraveny jak pro GNU Assembler (GAS), tak i (až na jednu výjimku) pro Netwide Assembler (NASM).
Obsah
1. Doplnění k předchozímu článku – příklady upravené Danem Horákem pro „big iron“
2. Použití assembleru v Linuxu: volání služeb nabízených jádrem
3. Strojové instrukce, které dnes budeme používat
4. Dvě syntaxe zápisu programů podporované GNU Assemblerem
5. Služba sys_write: zápis sekvence bajtů do souboru specifikovaného deskriptorem
6. Program typu „Hello world!“ napsaný v GNU Assembleru pro i386
7. Použití „Intel“ syntaxe pro program typu „Hello world“
8. Vizuální rozdíl: AT&T syntaxe versus Intel syntaxe
9. Přepis programu typu „Hello world!“ do syntaxe Netwide Assembleru (NASM)
10. Vizuální rozdíl: Intel syntaxe v GNU Assembleru versus NASM
11. Vylepšená verze výpočtu délky řetězce
12. Přepis programu pro architekturu S/390 a S/390x
13. Repositář se zdrojovými kódy demonstračních příkladů
1. Doplnění k předchozímu článku – příklady upravené Danem Horákem pro „big iron“
Ještě předtím, než se začneme zabývat tématem dnešního článku, se na chvíli vraťme k prvnímu dílu, v němž jsme si ukázali jednoduché „šablony“ s programy psanými v assembleru procesorů řady i386/x86-64 i 32bitových ARMů s instrukční sadou Thumb. Dan Horák, jemuž tímto posílám velké poděkování, tyto šablony upravil pro použití v Linuxu běžícího na „big ironu“, konkrétně na systémech (ať již reálných či emulovaných) S/390 (architektura s 31bitovým adresováním) a S/390x (již 64bitová architektura). Tyto příklady naleznete v GIT repositáři v adresáři 01_gas_template a 03_gas_hello_world (bude popsán níže), samozřejmě včetně skriptů pro překlad a slinkování. Pro zajímavost se na upravenou šablonu podívejme, neboť je na ní vidět rozdíl oproti ostatním dvěma architekturám:
Program, který se po svém spuštění ukončí zavoláním služby jádra sys_exit
# asmsyntax=as
# Sablona pro zdrojovy kod Linuxoveho programu naprogramovaneho
# v assembleru GNU AS.
#
# Autor: Pavel Tisnovsky
# Dan Horak
# Linux kernel system call table
sys_exit=1
#-----------------------------------------------------------------------------
.section .data
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
la 1,sys_exit # cislo sycallu pro funkci "exit"
la 2,0 # exit code = 0
svc 0 # volani Linuxoveho kernelu
# pro syscally < 256 funguje i nasledujici
# la 2,0
# svc sys_exit
Povšimněte si především způsobu zápisu jmen (či spíše indexů) pracovních registrů. Samotná služba jádra se volá instrukcí SVC neboli „Supervisor Call“.
Překlad a slinkování pro S/390:
as -m31 s390.s -o s390.o ld -melf_s390 -s s390.o
Překlad a slinkování pro S/390x:
as s390.s -o s390x.o ld -s s390x.o
2. Použití assembleru v Linuxu: volání služeb nabízených jádrem
V dnešním článku se budeme primárně zabývat základními službami nabízenými jádrem Linuxu. Již z úvodní části víme, že tyto služby lze snadno volat i z assembleru. Většinou pouze postačuje naplnit pracovní registry požadovanými parametry popř. adresami složitějších datových struktur uložených v operační paměti, nastavit číslo služby a následně provést přepnutí procesoru do režimu jádra. Na architektuře i386 se přepnutí provede instrukcí INT, která způsobí přerušení, jenž je obsluhované jádrem. Při programování je dobré mít na paměti, že takto realizovaná obsluha systémových volání je relativně pomalá, takže se například při vypisování řetězců na standardní výstup či do souboru vyplatí si ukládat výstupní data do bufferu a volat jádro až ve chvíli, kdy je to skutečně nutné (nikoli tedy po jednotlivých znacích). Samozřejmě lze použít i služby knihovny libc, což se pro složitější aplikace stává praktickou nezbytností.
Programy, které si ukážeme a odladíme dnes i v příští (třetí) části, budou používat následující tři systémová volání (syscally):
| Syscall | Číslo | Význam |
|---|---|---|
| sys_exit | 1 | ukončení procesu |
| sys_read | 3 | čtení přes deskriptor souboru (například standardního vstupu) |
| sys_write | 4 | zápis přes deskriptor souboru (například do standardního výstupu) |
3. Strojové instrukce, které dnes budeme používat
Pro jednoduchost se prozatím budeme soustředit především na procesory s architekturou i386 a x86-64 (jedinou výjimkou bude dvanáctá kapitola a programy vytvořené Danem Horákem pro S/390 a S/390x). Zajímavé je, že si prozatím vystačíme s pouhými několika strojovými instrukcemi resp. jejich variantami, které se od sebe odlišují použitými operandy. V následující tabulce je použita Intel syntaxe, která je podle mého názoru mnohem čitelnější, než syntaxe AT&T:
| # | Instrukce | Stručný popis |
|---|---|---|
| 1 | mov eax, 1 | uložení konstanty do registru eax |
| 2 | mov ecx, offset návěští | uložení adresy do registru ecx |
| 3 | mov [entered], eax | uložení registru na adresu zadanou návěštím |
| 4 | mod edx, [entered] | načtení 32bitového slova z adresy zadané návěštím |
| 5 | int 80h | volání jádra funkce (syscall) |
V režimu i386 lze používat 32bitové pracovní registry nazvané:
| Registr | Poznámka |
|---|---|
| EAX | univerzální registr |
| EBX | univerzální registr |
| ECX | univerzální registr |
| EDX | univerzální registr |
| ESI | index registr |
| EDI | index registr |
| EBP | index registr, někdy použit pro uložení báze zásobníkového rámce |
| ESP | použit pro adresování v rámci zásobníkového rámce |
V režimu x86-64 se bitová šířka pracovních registrů (používaných kromě běžných aritmetických a logických operací mj. i pro adresování) zvyšuje na plných šedesát čtyři bitů a navíc se namísto původní osmice pracovních 32bitových registrů EAX, EBX, ECX, EDX, EBP, ESP, ESI, EDI (viz předchozí tabulka) používá dvojnásobný počet pracovních registrů RAX, RBX, RCX, RDX, RBP, RSP, RSI, RDI, R8, R9, R10, R11, R12, R13, R14, R15.
4. Dvě syntaxe zápisu programů podporované GNU Assemblerem
Při použití GNU Assembleru na mikroprocesorech s architekturou i386 či x86-64 je možné použít dvě různé syntaxe zápisu programů. Proč vlastně k tomuto stavu došlo? Původní verze GNU Assembleru z historických důvodů používala zápis používaný v AT&T (resp. přesněji řečeno v Bell Labs při vývoji Unixu). Tento zápis je sice (samozřejmě jen do určité míry) konzistentní mezi různými platformami, ovšem pro mnoho programátorů pracujících na platformách s procesory s architekturou i386 je AT&T syntaxe velmi nezvyklá a taktéž nekompatibilní s dalšími typy assemblerů (Turbo Assembler – TASM, Microsoft Macro Assembler – MASM atd.). Proto mj. vznikl i projekt Netwide Assembler (NASM), který i na Linux (resp. přesněji řečeno do jeho toolchainu) přidal podporu pro zápis programů v assembleru podle zvyklostí z jiných systémů. Změny později nastaly i v GNU Assembleru, což mj. znamená, že od verze 2.10 je možné se jedinou direktivou přepnout do režimu částečně kompatibilního s TASM/MASM. Rozdíly mezi oběma způsoby zápisu si ukážeme na praktických příkladech v dalších kapitolách.
5. Služba sys_write: zápis sekvence bajtů do souboru specifikovaného deskriptorem
Prvním programem, s nímž se dnes seznámíme, je program typu „Hello world!“. Ten je možné v assembleru procesorů řady i386/x86-64 realizovat poměrně snadno, a to z toho důvodu, že samotné jádro operačního systému obsahuje systémové volání (syscall) pro zápis sekvence bajtů do souboru specifikovaného svým deskriptorem. My sice prozatím neumíme pracovat se soubory, to však vůbec nevadí, protože pro každý nový proces jsou automaticky vytvořeny tři deskriptory: standardní vstup, standardní výstup a chybový výstup. A právě standardní výstup použijeme pro výpis řetězce „Hello world!“. Na 32bitovém systému vypadá příslušný syscall takto:
| Registr | Význam | Obsah |
|---|---|---|
| eax | číslo syscallu | sys_write=4 |
| ebx | číslo deskriptoru | stdout=1 |
| ecx | adresa řetězce/bajtů | nastaví se do .data segmentu |
| edx | počet bajtů pro zápis | strlen("Hello world!\n")=13 |
6. Program typu „Hello world!“ napsaný v GNU Assembleru pro i386
Podívejme se, jak bude vypadat zápis programu typu „Hello world!“ napsaný v GNU Assembleru pro i386. Celý program vlastně volá jen dvě služby jádra: sys_write a sys_exit. U sys_write se nastaví registry způsobem popsaným ve výše uvedené tabulce. Zajímavý je obsah registru ecx, protože ten musí obsahovat adresu řetězce (resp. bloku bajtů). V AT&T syntaxi to vypadá následovně:
mov $hello_lbl,%ecx
Přičemž hello_lbl je návěští (label) neboli pojmenovaná adresa. Samotný řetězec leží v sekci .data, která je automaticky vkládána do výsledného binárního souboru. Povšimněte si, že řetězec není ukončen znakem s ASCII kódem 0. To není nutné, protože systémová služba přesně zná délku řetězce (bloku bajtů):
# asmsyntax=as
# Jednoducha aplikace typu "Hello world!" naprogramovana
# v assembleru GNU as.
#
# Autor: Pavel Tisnovsky
# Linux kernel system call table
sys_exit=1
sys_write=4
#-----------------------------------------------------------------------------
.section .data
hello_lbl:
.string "Hello World!\n"
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
mov $sys_write, %eax # cislo syscallu pro funkci "write"
mov $1,%ebx # standardni vystup
mov $hello_lbl,%ecx # adresa retezce, ktery se ma vytisknout
mov $13,%edx # pocet znaku, ktere se maji vytisknout
int $0x80 # volani Linuxoveho kernelu
movl $sys_exit,%eax # cislo sycallu pro funkci "exit"
movl $0,%ebx # exit code = 0
int $0x80 # volani Linuxoveho kernelu
Program přeložíme a slinkujeme následujícím způsobem:
as hello_world.s -o hello_world.o ld -s hello_world.o
Pokud vás zajímá, jak vypadá interní struktura vytvořeného spustitelného souboru a jaké (ladicí i jiné) symboly tento soubor obsahuje, můžete použít následující příkaz, který všechny potřebné informace dokáže získat a zobrazit v čitelné podobě. Nejzajímavější je v tomto okamžiku struktura nazvaná SYMBOL TABLE i zpětný překlad (disassembly):
objdump -f -d -t -h a.out
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00000000004000b0
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000022 00000000004000b0 00000000004000b0 000000b0 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 0000000e 00000000006000d2 00000000006000d2 000000d2 2**0
CONTENTS, ALLOC, LOAD, DATA
SYMBOL TABLE:
no symbols
Disassembly of section .text:
00000000004000b0 <.text>:
4000b0: b8 04 00 00 00 mov $0x4,%eax
4000b5: bb 01 00 00 00 mov $0x1,%ebx
4000ba: b9 d2 00 60 00 mov $0x6000d2,%ecx
4000bf: ba 0d 00 00 00 mov $0xd,%edx
4000c4: cd 80 int $0x80
4000c6: b8 01 00 00 00 mov $0x1,%eax
4000cb: bb 00 00 00 00 mov $0x0,%ebx
4000d0: cd 80 int $0x80
O tom, že se ve spustitelném souboru vyskytuje i řetězec „Hello world!“ se přesvědčíme příkazem strings:
$ strings a.out Hello World! .shstrtab .text .data
7. Použití „Intel“ syntaxe pro program typu „Hello world“
Podívejme se nyní, jak lze zapsat tu stejnou aplikaci, ovšem s použitím Intel syntaxe. První změnou je použití přepínače:
.intel_syntax noprefix
Dále se prohodily operandy všech instrukcí, takže u instrukce mov je na prvním místě cílový registr (či adresa) a na místě druhém zdrojový registr, adresa či konstanta. U jmen registrů se nemusí uvádět znak dolaru a poslední významnou změnou je odlišný zápis při načítání adresy do registru:
mov $hello_lbl,%ecx # adresa retezce, ktery se ma vytisknout versus mov ecx, offset hello_lbl # adresa retezce, ktery se ma vytisknout
Úplný program vypadá následovně:
# asmsyntax=as
# Jednoducha aplikace typu "Hello world!" naprogramovana
# v assembleru GNU as - pouzita je "Intel" syntaxe.
#
# Autor: Pavel Tisnovsky
.intel_syntax noprefix
# Linux kernel system call table
sys_exit=1
sys_write=4
#-----------------------------------------------------------------------------
.section .data
hello_lbl:
.string "Hello World!\n" # string, ktery JE ukoncen nulou
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
mov eax, sys_write # cislo syscallu pro funkci "write"
mov ebx, 1 # standardni vystup
mov ecx, offset hello_lbl # adresa retezce, ktery se ma vytisknout
mov edx, 13 # pocet znaku, ktere se maji vytisknout
int 0x80 # volani Linuxoveho kernelu
mov eax, sys_exit # cislo sycallu pro funkci "exit"
mov ebx, 0 # exit code = 0
int 0x80 # volani Linuxoveho kernelu
Program přeložíme a slinkujeme stejným způsobem, jako předchozí verzi:
as hello_world.s -o hello_world.o ld -s hello_world.o
Při zkoumání výsledného spustitelného binárního souboru máme dvě možnosti. Buď použít nám již známé volání, které používá disassembler kompatibilní se syntaxí AT&T:
objdump -f -d -t -h a.out
Alternativně je však možné se přepnout i na syntaxi kompatibilní s překladači typu NASM či TASM:
objdump -M intel-mnemonic -f -d -t -h a.out
Ve druhém případě bude výsledek do značné míry podobný původnímu zdrojovému kódu:
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00000000004000b0
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000022 00000000004000b0 00000000004000b0 000000b0 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 0000000e 00000000006000d2 00000000006000d2 000000d2 2**0
CONTENTS, ALLOC, LOAD, DATA
SYMBOL TABLE:
no symbols
Disassembly of section .text:
00000000004000b0 <.text>:
4000b0: b8 04 00 00 00 mov eax,0x4
4000b5: bb 01 00 00 00 mov ebx,0x1
4000ba: b9 d2 00 60 00 mov ecx,0x6000d2
4000bf: ba 0d 00 00 00 mov edx,0xd
4000c4: cd 80 int 0x80
4000c6: b8 01 00 00 00 mov eax,0x1
4000cb: bb 00 00 00 00 mov ebx,0x0
4000d0: cd 80 int 0x80
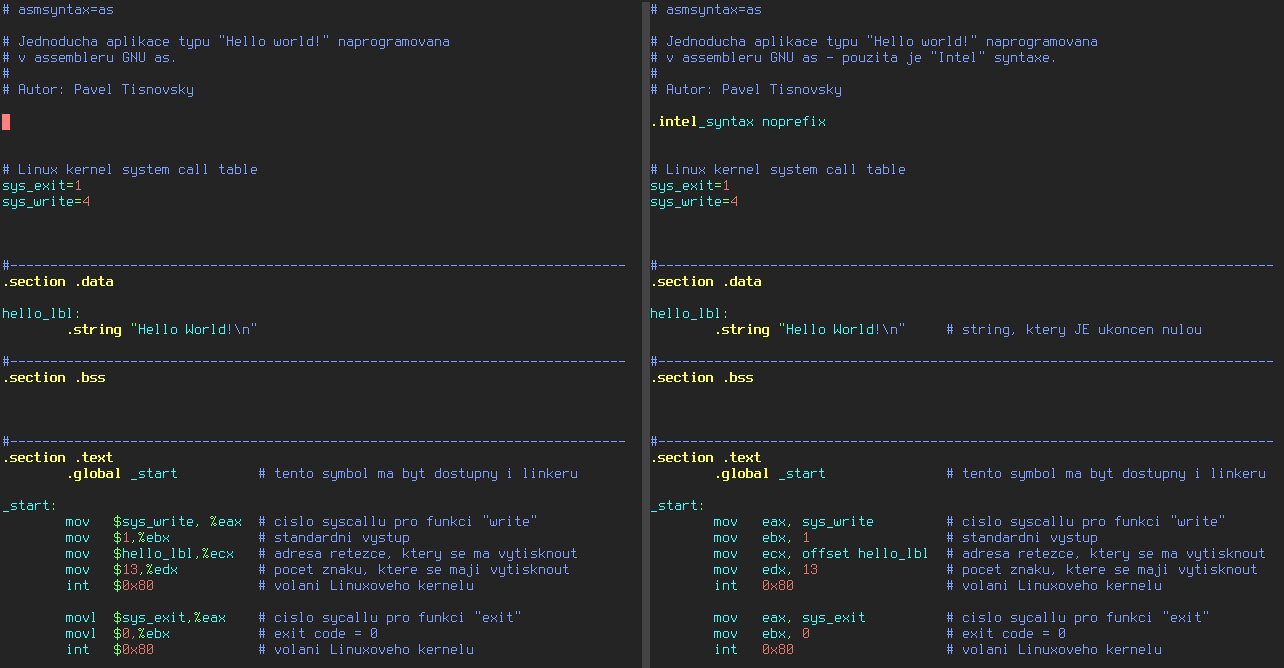
8. Vizuální rozdíl: AT&T syntaxe versus Intel syntaxe
Rozdíly mezi oběma způsoby zápisu jsou dobře patrné ve chvíli, kdy si oba zdrojové soubory zobrazíme vedle sebe, což je provedeno na následujícím screenshotu:
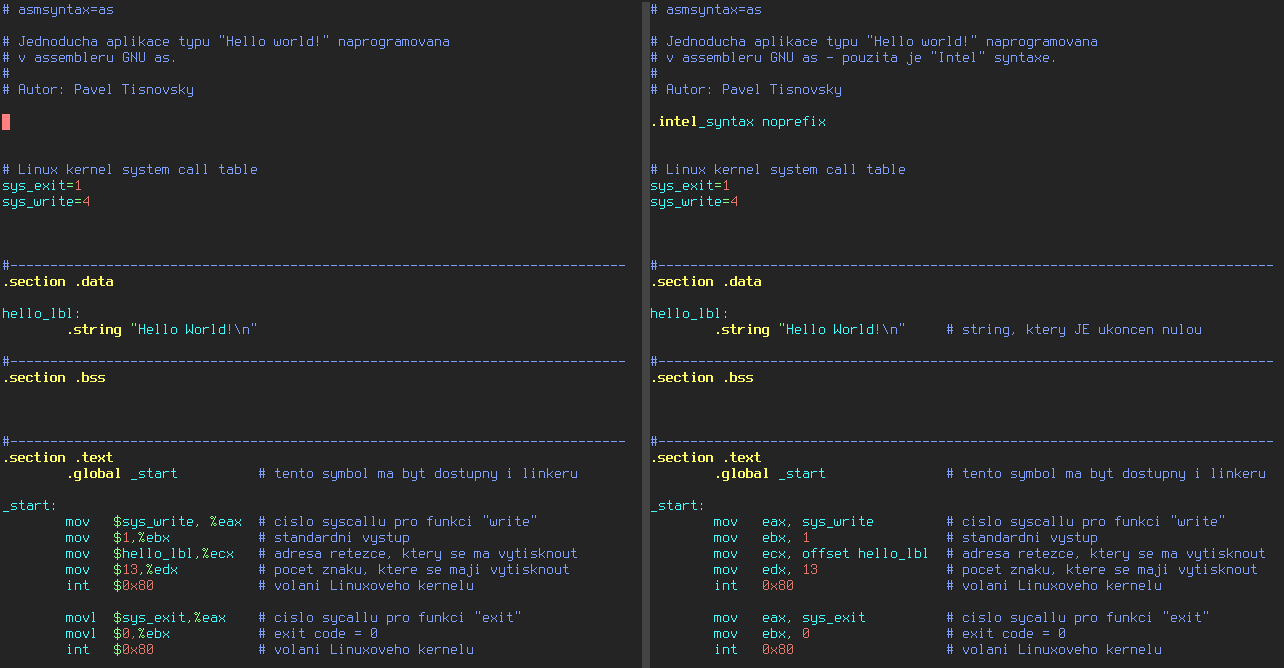
Obrázek ve vyšším rozlišení naleznete na adrese https://raw.githubusercontent.com/tisnik/presentations/master/assembler/att_vs_intel.png.
Poznámka: oba výsledné soubory jsou po překladu do nativního kódu samozřejmě zcela identické!
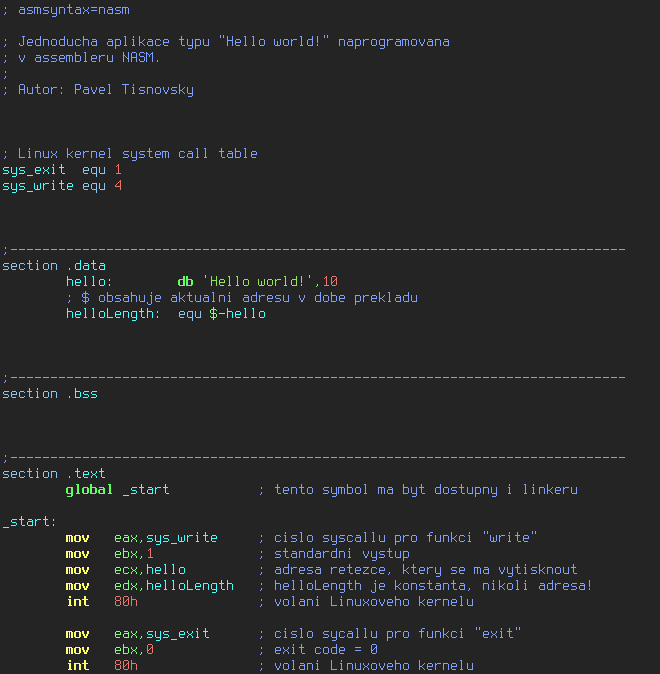
9. Přepis programu typu „Hello world!“ do syntaxe Netwide Assembleru (NASM)
Pokusme se nyní přepsat program z GNU Assembleru do Netwide Assembleru (NASM). Uvidíme, že samotný zápis je sice v mnoha ohledech odlišný (jiný formát komentářů či zápisů konstant, zjednodušení při práci s adresami), ovšem základní koncepty zůstávají zachovány. Nejdříve se podívejme na zdrojový kód programu. Samotný popis rozdílů bude uveden posléze:
; asmsyntax=nasm
; Jednoducha aplikace typu "Hello world!" naprogramovana
; v assembleru NASM.
;
; Autor: Pavel Tisnovsky
; Linux kernel system call table
sys_exit equ 1
sys_write equ 4
;-----------------------------------------------------------------------------
section .data
hello: db 'Hello world!',10
;-----------------------------------------------------------------------------
section .bss
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
mov eax,sys_write ; cislo syscallu pro funkci "write"
mov ebx,1 ; standardni vystup
mov ecx,hello ; adresa retezce, ktery se ma vytisknout
mov edx,13 ; pocet znaku, ktere se maji vytisknout
int 80h ; volani Linuxoveho kernelu
mov eax,sys_exit ; cislo sycallu pro funkci "exit"
mov ebx,0 ; exit code = 0
int 80h ; volani Linuxoveho kernelu
Vidíme, že se liší zápis komentářů, které zde začínají znakem středníku. U GNU Assembleru je práce s komentáři poněkud problematická, protože na různých architekturách se používají odlišné znaky (zavináč atd.). Středníky mají výhodu ve snadném zápisu (bez shiftu) i v dlouhé tradici použití tohoto znaku i v jiných assemblerech (opět viz TASM a MASM). Odlišný je taktéž způsob deklarace konstant, protože pro celočíselné konstanty je nutné použít zápis jméno equ hodnota (opět se jedná o určitou tradici, i když s poněkud horší čitelností oproti zápisu jméno=hodnota). Rozdíl je i v deklaraci řetězce, kdy se používá zápis:
hello: db 'Hello world!',10
U tohoto zápisu je zajímavé, že se skutečně předepisuje vytvoření bloku bajtů zakončeného hodnotou 10 (konec řádku), zatímco v případě GNU Assembleru se navíc za řetězec vložila nula, která je zde zhola zbytečná (nejedná se o céčkový řetězec ani s ním tak nepracujeme). Mimochodem, db znamená „define byte“, samozřejmě se tedy můžeme setkat i s deklaracemi dw („define word“), dd („define double word“) či dq („define quad word“). Poslední viditelnou změnou je určité zjednodušení načtení adresy, kdy se (v některých případech) nemusí používat pomocné slovo offset ani byte ptr apod. Pokud by se namísto adresy mělo pracovat přímo s hodnotou uloženou na této adrese, je nutné použít složené závory (což si ukážeme příště).
Překlad na 32bitové architektuře zajistí příkazy:
nasm -felf32 hello_world.asm ld -s hello_world.o
Na 64bitové architektuře použijeme mírně odlišný zápis:
nasm -felf64 hello_world.asm ld -s hello_world.o
Jen pro zajímavost se můžeme přesvědčit, že se překlad provedl (až na chybějící nulu na konci řetězce) stejně, jako v předchozím příkladu (liší se délka sekce .data o jedničku):
$ ./disassemble
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00000000004000b0
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000022 00000000004000b0 00000000004000b0 000000b0 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 0000000d 00000000006000d4 00000000006000d4 000000d4 2**2
CONTENTS, ALLOC, LOAD, DATA
SYMBOL TABLE:
no symbols
Disassembly of section .text:
00000000004000b0 <.text>:
4000b0: b8 04 00 00 00 mov $0x4,%eax
4000b5: bb 01 00 00 00 mov $0x1,%ebx
4000ba: b9 d4 00 60 00 mov $0x6000d4,%ecx
4000bf: ba 0d 00 00 00 mov $0xd,%edx
4000c4: cd 80 int $0x80
4000c6: b8 01 00 00 00 mov $0x1,%eax
4000cb: bb 00 00 00 00 mov $0x0,%ebx
4000d0: cd 80 int $0x80
10. Vizuální rozdíl: Intel syntaxe v GNU Assembleru versus NASM
Opět se podívejme na rozdíly mezi oběma způsoby zápisu. Budeme porovnávat zápis programu v GNU Assembleru při použití syntaxe Intel a zápis programu v Netwide Assembleru (porovnání syntaxe AT&T s NASM by totiž nebylo příliš přínosné, rozdílů je zde příliš mnoho):
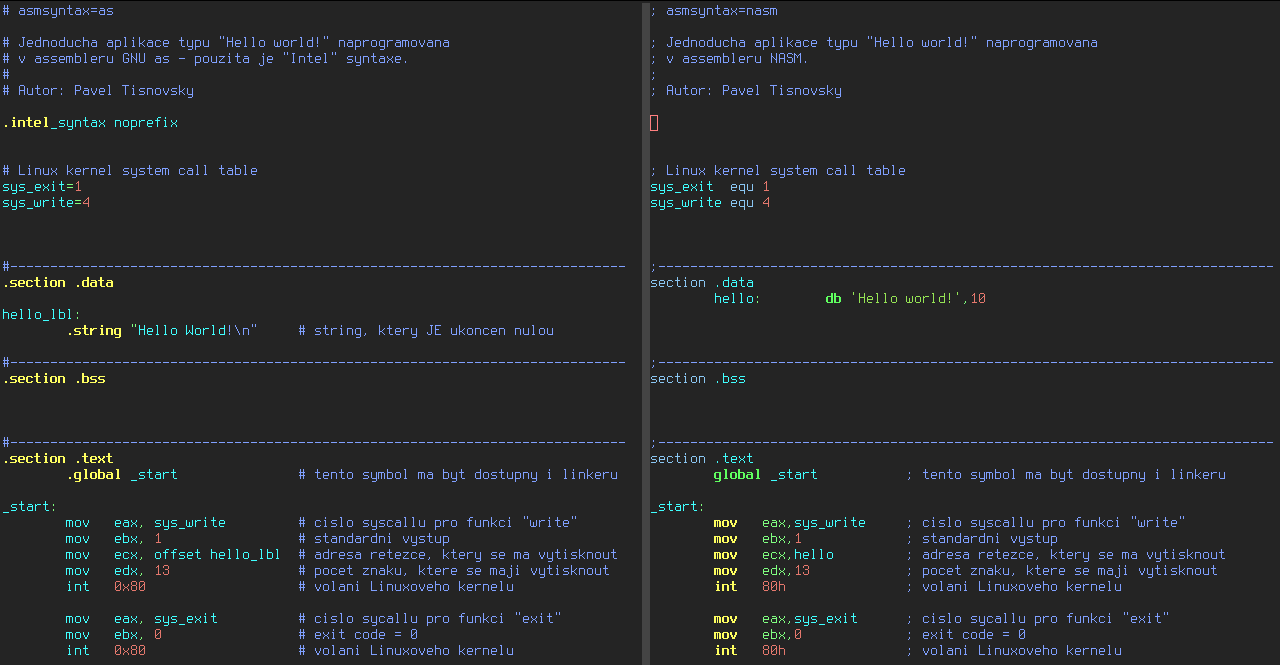
Obrázek ve vyšším rozlišení naleznete na adrese https://raw.githubusercontent.com/tisnik/presentations/master/assembler/gas_vs_nasm.png.
11. Vylepšená verze výpočtu délky řetězce
Programy, které jsme si až doposud ukazovali, měly jednu nepříjemnou vlastnost – při volání systémové funkce sys_write jsme museli zadávat délku řetězce formou konstanty (13), kterou jsme vypočetli ručně. Pokud by se řetězec změnil, bylo by nutné tuto konstantu ve zdrojovém kódu najít a opravit. Ve skutečnosti však můžeme program vylepšit, a to relativně jednoduchým trikem. Nejdříve se podívejme, jak se tento trik zapisuje:
hello: db 'Hello world!',10 ; $ obsahuje aktualni adresu v dobe prekladu helloLength equ $-hello
Nejdříve je deklarován blok bajtů obsahující řetězec ukončený znakem pro odřádkování, což pro nás není nic nového. Následně je ovšem použit zápis $-hello. Znak $ má v Netwide assembleru (ale nejenom zde) speciální význam, protože je nahrazen za aktuální adresu spočtenou v době překladu pro daný programový řádek (resp. pro jeho začátek). Tato adresa odpovídá adrese návěští hello zvýšené přesně o délku řetězce, což znamená, že výpočet probíhá při překladu takto $-hello=(hello+délka_řetězce)-hello=délka_řetězce. A tato hodnota přesně odpovídá hodnotě, kterou musíme předat systémovému volání:
; asmsyntax=nasm
; Jednoducha aplikace typu "Hello world!" naprogramovana
; v assembleru NASM.
;
; Autor: Pavel Tisnovsky
; Linux kernel system call table
sys_exit equ 1
sys_write equ 4
;-----------------------------------------------------------------------------
section .data
hello: db 'Hello world!',10
; $ obsahuje aktualni adresu v dobe prekladu
helloLength equ $-hello
;-----------------------------------------------------------------------------
section .bss
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
mov eax,sys_write ; cislo syscallu pro funkci "write"
mov ebx,1 ; standardni vystup
mov ecx,hello ; adresa retezce, ktery se ma vytisknout
mov edx,helloLength ; helloLength je konstanta, nikoli adresa!
int 80h ; volani Linuxoveho kernelu
mov eax,sys_exit ; cislo sycallu pro funkci "exit"
mov ebx,0 ; exit code = 0
int 80h ; volani Linuxoveho kernelu
Překlad a slinkování se provede naprosto stejným způsobem, jako tomu bylo v předchozím příkladu.
12. Přepis programu pro architekturu S/390 a S/390x
Pro zajímavost se podívejme, jak se „Hello world!“ napíše pro mainframy S/390 a S/390x. Tuto úpravu provedl Dan Horák, kterému opět děkuji:
Program „Hello world“ pro S/390
# asmsyntax=as
# Jednoducha aplikace typu "Hello world!" naprogramovana
# v assembleru GNU as.
#
# Autor: Pavel Tisnovsky
# Dan Horak
# Linux kernel system call table
sys_exit=1
sys_write=4
#-----------------------------------------------------------------------------
.section .data
hello_lbl:
.string "Hello World!\n"
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
basr 13,0 # nastaveni literal poolu
.L0: ahi 13,.LT0-.L0
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,1 # standardni vystup
l 3,.LC1-.LT0(13) # adresa retezce, ktery se ma vytisknout
la 4,13 # pocet znaku, ktere se maji vytisknout
svc 0 # volani Linuxoveho kernelu
la 1,sys_exit # cislo sycallu pro funkci "exit"
la 2,0 # exit code = 0
svc 0 # volani Linuxoveho kernelu
# literal pool
.LT0:
.LC1: .long hello_lbl
Program „Hello world“ pro S/390x
Verze pro 64bitovou architekturu je jednodušší a do značné míry odpovídá variantě aplikace určené pro procesory s architekturou i386. Odlišují se jen jména registrů (zde pouze indexy) a mnemotechnické zkratky instrukcí (SVC=Supervisor Call atd.):
# asmsyntax=as
# Jednoducha aplikace typu "Hello world!" naprogramovana
# v assembleru GNU as.
#
# Autor: Pavel Tisnovsky
# Dan Horak
# Linux kernel system call table
sys_exit=1
sys_write=4
#-----------------------------------------------------------------------------
.section .data
hello_lbl:
.string "Hello World!\n"
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,1 # standardni vystup
larl 3,hello_lbl # adresa retezce, ktery se ma vytisknout
la 4,13 # pocet znaku, ktere se maji vytisknout
svc 0 # volani Linuxoveho kernelu
la 1,sys_exit # cislo sycallu pro funkci "exit"
la 2,0 # exit code = 0
svc 0 # volani Linuxoveho kernelu
Poznámka: trik s výpočtem délky řetězce s využitím $ je samozřejmě možné provést i v tomto příkladu.
13. Repositář se zdrojovými kódy demonstračních příkladů
Všechny dnes popisované demonstrační příklady byly společně s podpůrnými skripty uloženy do GIT repositáře dostupného na adrese https://github.com/tisnik/presentations/. Následuje tabulka s odkazy na zdrojové kódy příkladů i na již zmíněné podpůrné skripty:
Hello world v GNU Assembleru
| # | Soubor | Popis | Odkaz do repositáře |
|---|---|---|---|
| 1 | hello_world.s | program pro i386/x86-64 | https://github.com/tisnik/presentations/blob/master/assembler/03_gas_hello_world/hello_world.s |
| 2 | hello_world-s390.s | program pro s/390 | https://github.com/tisnik/presentations/blob/master/assembler/03_gas_hello_world/hello_world-s390.s |
| 3 | hello_world-s390x.s | program pro s/390x | https://github.com/tisnik/presentations/blob/master/assembler/03_gas_hello_world/hello_world-s390x.s |
| 4 | as_ibm_s390 | skript pro překlad na s/390 | https://github.com/tisnik/presentations/blob/master/assembler/03_gas_hello_world/as_ibm_s390 |
| 5 | as_ibm_s390x | skript pro překlad na s/390x | https://github.com/tisnik/presentations/blob/master/assembler/03_gas_hello_world/as_ibm_s390x |
| 6 | assemble | skript pro překlad na i386 | https://github.com/tisnik/presentations/blob/master/assembler/03_gas_hello_world/assemble |
| 7 | disassemble | skript pro disassembling | https://github.com/tisnik/presentations/blob/master/assembler/03_gas_hello_world/disassemble |

Hello world v GNU Assembleru, Intel syntaxe
| # | Soubor | Popis | Odkaz do repositáře |
|---|---|---|---|
| 1 | hello_world.s | program pro i386/x86-64 | https://github.com/tisnik/presentations/blob/master/assembler/06_gas_intel_hello_world/hello_world.s |
| 2 | assemble | skript pro překlad na i386 | https://github.com/tisnik/presentations/blob/master/assembler/06_gas_intel_hello_world/assemble |
| 3 | disassemble | skript pro disassembling | https://github.com/tisnik/presentations/blob/master/assembler/06_gas_intel_hello_world/disassemble |
Hello world v Netwide Assembleru
| # | Soubor | Popis | Odkaz do repositáře |
|---|---|---|---|
| 1 | hello_world.asm | program pro NASM | https://github.com/tisnik/presentations/blob/master/assembler/04_nasm_hello_world_A/hello_world.asm |
| 2 | assemble_i386 | skript pro překlad na i386 | https://github.com/tisnik/presentations/blob/master/assembler/04_nasm_hello_world_A/assemble_i386 |
| 3 | assemble_x86_64 | skript pro překlad na x86/64 | https://github.com/tisnik/presentations/blob/master/assembler/04_nasm_hello_world_A/assemble_x86_64 |
| 4 | disassemble | skript pro disassembling | https://github.com/tisnik/presentations/blob/master/assembler/04_nasm_hello_world_A/disassemble |
Hello world v Netwide Assembleru, vylepšený výpočet délky řetězce
| # | Soubor | Popis | Odkaz do repositáře |
|---|---|---|---|
| 1 | hello_world.asm | program pro NASM | https://github.com/tisnik/presentations/blob/master/assembler/05_nasm_hello_world_B/hello_world.asm |
| 2 | assemble_i386 | skript pro překlad na i386 | https://github.com/tisnik/presentations/blob/master/assembler/05_nasm_hello_world_B/assemble_i386 |
| 3 | assemble_x86_64 | skript pro překlad na x86/64 | https://github.com/tisnik/presentations/blob/master/assembler/05_nasm_hello_world_B/assemble_x86_64 |
| 4 | disassemble | skript pro disassembling | https://github.com/tisnik/presentations/blob/master/assembler/05_nasm_hello_world_B/disassemble |
14. Odkazy na Internetu
- Linux assemblers: A comparison of GAS and NASM
http://www.ibm.com/developerworks/library/l-gas-nasm/index.html - Programovani v assembleru na OS Linux
http://www.cs.vsb.cz/grygarek/asm/asmlinux.html - Is it worthwhile to learn x86 assembly language today?
https://www.quora.com/Is-it-worthwhile-to-learn-x86-assembly-language-today?share=1 - Why Learn Assembly Language?
http://www.codeproject.com/Articles/89460/Why-Learn-Assembly-Language - Is Assembly still relevant?
http://programmers.stackexchange.com/questions/95836/is-assembly-still-relevant - Why Learning Assembly Language Is Still a Good Idea
http://www.onlamp.com/pub/a/onlamp/2004/05/06/writegreatcode.html - Assembly language today
http://beust.com/weblog/2004/06/23/assembly-language-today/ - Assembler: Význam assembleru dnes
http://www.builder.cz/rubriky/assembler/vyznam-assembleru-dnes-155960cz - Assembler pod Linuxem
http://phoenix.inf.upol.cz/linux/prog/asm.html - AT&T Syntax versus Intel Syntax
https://www.sourceware.org/binutils/docs-2.12/as.info/i386-Syntax.html - Linux Assembly website
http://asm.sourceforge.net/ - Using Assembly Language in Linux
http://asm.sourceforge.net/articles/linasm.html - vasm
http://sun.hasenbraten.de/vasm/ - vasm – dokumentace
http://sun.hasenbraten.de/vasm/release/vasm.html - The Yasm Modular Assembler Project
http://yasm.tortall.net/ - 680x0:AsmOne
http://www.amigacoding.com/index.php/680x0:AsmOne - ASM-One Macro Assembler
http://en.wikipedia.org/wiki/ASM-One_Macro_Assembler - ASM-One pages
http://www.theflamearrows.info/documents/asmone.html - Základní informace o ASM-One
http://www.theflamearrows.info/documents/asminfo.html - Linux Syscall Reference
http://syscalls.kernelgrok.com/ - Programming from the Ground Up Book - Summary
http://savannah.nongnu.org/projects/pgubook/ - IBM System 360/370 Compiler and Historical Documentation
http://www.edelweb.fr/Simula/ - IBM 700/7000 series
http://en.wikipedia.org/wiki/IBM_700/7000_series - IBM System/360
http://en.wikipedia.org/wiki/IBM_System/360 - IBM System/370
http://en.wikipedia.org/wiki/IBM_System/370 - Mainframe family tree and chronology
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_FT1.html - 704 Data Processing System
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP704.html - 705 Data Processing System
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP705.html - The IBM 704
http://www.columbia.edu/acis/history/704.html - IBM Mainframe album
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_album.html - Osmibitové muzeum
http://osmi.tarbik.com/ - Tesla PMI-80
http://osmi.tarbik.com/cssr/pmi80.html - PMI-80
http://en.wikipedia.org/wiki/PMI-80 - PMI-80
http://www.old-computers.com/museum/computer.asp?st=1&c=1016

{kind=link}
{kind=link}