
Ve třetí části článku o použití assembleru v Linuxu si ukážeme složitější program reagující na uživatelský vstup. Tento program bude napsán v několika variantách – pro architekturu i386/x86_64, dále pro architektury s/390 a s/390x a nezapomeneme ani na původní 32bitovou architekturu ARM, protože právě u této stále oblíbené architektury má význam se assemblerem podrobněji zabývat kvůli velké popularitě různých jednodeskových mikropočítačů. A právě u architektury ARM se seznámíme s problematikou práce s 32bitovými konstantami.
Obsah
1. Použití assembleru v Linuxu: problematika systémové funkce sys_read
2. Služba sys_read: přečtení sekvence bajtů ze souboru specifikovaného deskriptorem
4. Konverze programu pro architekturu s/390
5. Druhá konverze programu, tentokrát pro architekturu s/390x
6. Konverze programu pro architekturu ARM
7. Specifika původní instrukční sady ARM a způsob řešení adresování v assembleru
8. Výsledná podoba přeloženého binárního kódu pro ARM
9. Přepis programu pro čtení vstupu od uživatele do syntaxe NASMu
10. Otestování programu a zjištění některých problémů
11. Repositář s demonstračními příklady
1. Použití assembleru v Linuxu: problematika systémové funkce sys_read
Ve třetí části seriálu o použití assembleru (jazyka symbolických adres) při tvorbě aplikací pro Linux navážeme na první i druhý díl, protože dokončíme problematiku volání služeb jádra (syscalls). Ukážeme si několik verzí jednoduchého programu, který budeme postupně vylepšovat a hledat v něm chyby. Tento program bude vyhotoven v několika variantách. První varianta bude připravena pro procesory s architekturou i386/x86_64, další dvě varianty pak pro architektury s/390 a s/390x a nejzajímavější bude pravděpodobně varianta určená pro 32bitové mikroprocesory s architekturou ARM. Zde si ukážeme několik zvláštností vyplývajících z RISCové instrukční sady těchto mikroprocesorů a tím i z nemožnosti zapsat do jediné instrukce plnou 32bitovou adresu.
Pro připomenutí si ještě jednou uveďme tabulku se základními funkcemi jádra Linuxu, které budeme volat z programů napsaných v assembleru. První funkce nazvaná sys_exit je nejjednodušší, protože pouze program ukončí a předá shellu návratový kód. Tuto funkci musíme zavolat na konci každého programu. Funkce pojmenovaná sys_read slouží pro čtení z otevřeného souboru (například ze standardního vstupu), zatímco funkce nazvaná sys_write naopak dokáže zapsat data do otevřeného souboru (například do standardního či chybového výstupu):
| Syscall | Číslo | Význam |
|---|---|---|
| sys_exit | 1 | ukončení procesu |
| sys_read | 3 | čtení přes deskriptor souboru (například standardního vstupu) |
| sys_write | 4 | zápis přes deskriptor souboru (například do standardního výstupu) |

Obrázek 1: Program „Hello world!“ naprogramovaný v GNU Assembleru pro i386.
2. Služba sys_read: přečtení sekvence bajtů ze souboru specifikovaného deskriptorem
Podívejme se nyní podrobněji na systémovou funkci nazvanou sys_read, která je sice „opakem“ funkce sys_write, ovšem při jejím programování si musíme dát větší pozor na to, aby nedošlo k přepsání jiné oblasti paměti, než jakou jsme alokovali pro vstup od uživatele. Systémová funkce sys_read vyžaduje několik parametrů, jejichž význam je vypsán v navazující tabulce:
| Parametr | Obsah | Registr (i386) | Registr (ARM 32bit) | Registr (s/390) |
|---|---|---|---|---|
| číslo syscallu | sys_read=3 | eax | r7 | 1 |
| číslo file deskriptoru | std_input=0 | ebx | r0 | 2 |
| adresa bufferu | adresa | ecx | r1 | 3 |
| max.délka vstupu | počet bajtů | edx | r2 | 4 |
Poznámka: buffer je typicky alokován v .data sekci a musí být dostatečně rozsáhlý, aby nedošlo k přepsání dalších dat.
Tato funkce v případě úspěchu vrátí počet přečtených bajtů v registru eax/r7/1, takže lze provést test, kolik bajtů bylo ve skutečnosti přečteno, zda byl vůbec nějaký vstup přečten či zda došlo k nějaké chybě. My dnes pro jednoduchost budeme předpokládat, že čtení ze standardního vstupu proběhne vždy bez chyby, což je možná příliš optimistické, ale prozatím nevíme, jak se v assembleru provádí testy a rozeskoky (větvení).
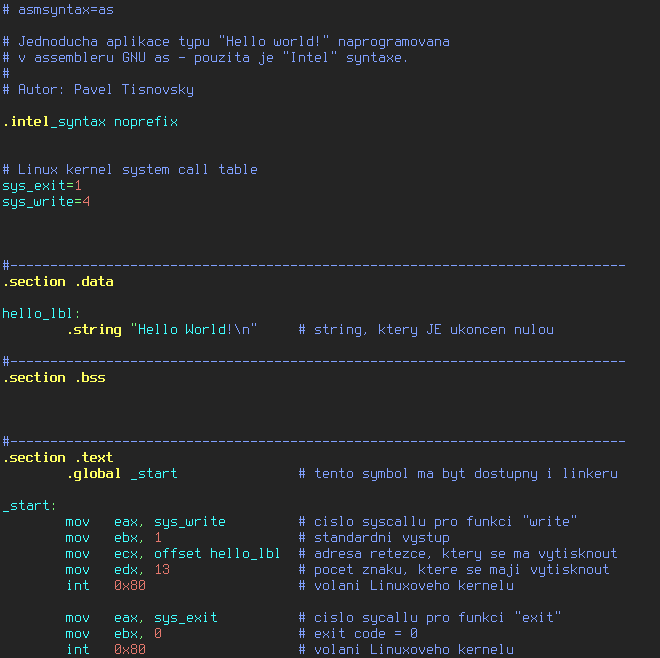
Obrázek 2: Program „Hello world!“ naprogramovaný v GNU Assembleru pro i386, tentokrát při použití Intel syntaxe.
3. Program, který přečte a vytiskne vstup od uživatele: verze pro GNU Assembler pro architekturu x86_64
Program, který si dnes ukážeme, se skládá z několika částí:
- Vytištění první zprávy uživateli: „Enter your name: “ (i s mezerou na konci, ovšem bez odřádkování)
- Přečtení sekvence bajtů (jména) ze standardního vstupu
- Vytištění druhé zprávy uživateli: „Hello “ (i s mezerou na konci, ovšem bez odřádkování)
- Vytištění jména získaného od uživatele
- Ukončení aplikace
Pro krok číslo 1, 3 a 4 se používá funkce sys_write, pro krok číslo 2 funkce sys_read a konečně pro krok číslo 5 funkce sys_exit.
V programu se objevuje novinka, se kterou jsme se doposud ještě nesetkali – je to deklarace bufferu umístěného v sekci .bss. Tato sekce byla v předchozích programech prázdná, protože jsme používali jen sekci .data pro inicializovaná data (například řetězce) a sekci .text pro vlastní strojový kód. Sekce .bss je zvláštní tím, že její obsah nemusí být ukládán do výsledného binárního souboru, takže se vlastně jedná o obdobu haldy. My zde vytvoříme místo pro buffer s maximálně padesáti bajty deklarací .lcomm input, 50:
# asmsyntax=as
# Aplikace pro precteni dat ze standardniho vstupu
# naprogramovana v assembleru GNU as - pouzita je "Intel" syntaxe.
#
# Autor: Pavel Tisnovsky
.intel_syntax noprefix
# Linux kernel system call table
sys_exit = 1
sys_read = 3
sys_write = 4
# Dalsi konstanty pouzite v programu - standardni streamy
std_input = 0
std_output = 1
#-----------------------------------------------------------------------------
.section .data
message1:
.ascii "Enter your name: " # string, ktery NENI ukoncen nulou
message1len = $ - message1 # delka prvni zpravy
message2:
.ascii "Hello " # string, ktery NENI ukoncen nulou
message2len = $ - message2 # delka druhe zpravy
#-----------------------------------------------------------------------------
.section .bss
.lcomm input, 50 # rezervace 50 bajtu pro vstup
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
# tisk prvni zpravy (vyzvy)
mov eax, sys_write # cislo syscallu pro funkci "write"
mov ebx, std_output # standardni vystup
mov ecx, offset message1 # adresa retezce, ktery se ma vytisknout
mov edx, message1len # pocet znaku, ktere se maji vytisknout
int 0x80 # volani Linuxoveho kernelu
# precteni vstupu od uzivatele
mov eax, sys_read # cislo syscallu pro funkci "read"
mov ebx, std_input # standardni vstup
mov ecx, offset input # adresa bufferu
mov edx, 50 # maximalni delka zpravy
int 0x80 # volani Linuxoveho kernelu
# tisk druhe zpravy (zacatek odpovedi)
mov eax, sys_write # cislo syscallu pro funkci "write"
mov ebx, std_output # standardni vystup
mov ecx, offset message2 # adresa retezce, ktery se ma vytisknout
mov edx, message2len # pocet znaku, ktere se maji vytisknout
int 0x80 # volani Linuxoveho kernelu
# tisk vstupu od uzivatele
mov eax, sys_write # cislo syscallu pro funkci "write"
mov ebx, std_output # standardni vystup
mov ecx, offset input # adresa bufferu
mov edx, 50 # delka (max delka)
int 0x80 # volani Linuxoveho kernelu
mov eax, sys_exit # cislo sycallu pro funkci "exit"
mov ebx, 0 # exit code = 0
int 0x80 # volani Linuxoveho kernelu
Překlad proběhne stejným způsobem, jaký již známe z předchozích dílů:
as read_input.s -o read_input.o ld -s read_input.o
Pokud vás zajímá obsah vytvořeného souboru (měl by), je to velmi snadné (povšimněte si přepínače -M intel-mnemonic:
objdump -M intel-mnemonic -f -d -t -h a.out
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00000000004000b0
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000064 00000000004000b0 00000000004000b0 000000b0 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000017 0000000000600114 0000000000600114 00000114 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000038 0000000000600130 0000000000600130 0000012b 2**3
ALLOC
SYMBOL TABLE:
no symbols
Disassembly of section .text:
00000000004000b0 <.text>:
4000b0: b8 04 00 00 00 mov eax,0x4
4000b5: bb 01 00 00 00 mov ebx,0x1
4000ba: b9 14 01 60 00 mov ecx,0x600114
4000bf: ba 11 00 00 00 mov edx,0x11
4000c4: cd 80 int 0x80
4000c6: b8 03 00 00 00 mov eax,0x3
4000cb: bb 00 00 00 00 mov ebx,0x0
4000d0: b9 30 01 60 00 mov ecx,0x600130
4000d5: ba 32 00 00 00 mov edx,0x32
4000da: cd 80 int 0x80
4000dc: b8 04 00 00 00 mov eax,0x4
4000e1: bb 01 00 00 00 mov ebx,0x1
4000e6: b9 25 01 60 00 mov ecx,0x600125
4000eb: ba 06 00 00 00 mov edx,0x6
4000f0: cd 80 int 0x80
4000f2: b8 04 00 00 00 mov eax,0x4
4000f7: bb 01 00 00 00 mov ebx,0x1
4000fc: b9 30 01 60 00 mov ecx,0x600130
400101: ba 32 00 00 00 mov edx,0x32
400106: cd 80 int 0x80
400108: b8 01 00 00 00 mov eax,0x1
40010d: bb 00 00 00 00 mov ebx,0x0
400112: cd 80 int 0x80
Povšimněte si dvou maličkostí:
- Obě zprávy vypisované uživateli jsou uloženy na adresách 0x600114 a 0x600125 ležících v sekci .data (viz části „sections“)
- Naproti tomu buffer začíná na adrese 0x600130, která již náleží do sekce .bss
4. Konverze programu pro architekturu s/390
Podobně jako v minulé části, i v části dnešní si uvedeme přepis výše uvedeného programu na architekturu s/390. Tuto konverzi opět provedl Dan Horák, kterému tímto děkuji, a kromě odlišného instrukčního souboru, pojmenování registrů a adresování bufferu i zpráv je vlastně zbytek celé aplikace stejný, což je o to překvapivější, že architektura s/390 je od dnes pravděpodobně nejběžnější architektury i386/x86_64 velmi odlišná (ovšem podobnost programů je mj. způsobena i tím, že stále pouze voláme funkce jádra systému a neprovádíme žádné složitější operace):
# asmsyntax=as
# Aplikace pro precteni dat ze standardniho vstupu
# naprogramovana v assembleru GNU as.
#
# Autor: Pavel Tisnovsky
# Dan Horák
# Linux kernel system call table
sys_exit = 1
sys_read = 3
sys_write = 4
# Dalsi konstanty pouzite v programu - standardni streamy
std_input = 0
std_output = 1
#-----------------------------------------------------------------------------
.section .data
message1:
.ascii "Enter your name: " # string, ktery NENI ukoncen nulou
message1len = . - message1 # delka prvni zpravy
message2:
.ascii "Hello " # string, ktery NENI ukoncen nulou
message2len = . - message2 # delka druhe zpravy
#-----------------------------------------------------------------------------
.section .bss
.lcomm input, 50 # rezervace 50 bajtu pro vstup
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
basr 13,0 # nastaveni literal poolu
.L0: ahi 13,.LT0-.L0
# tisk prvni zpravy (vyzvy)
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,std_output # standardni vystup
l 3,.LC1-.LT0(13) # adresa retezce, ktery se ma vytisknout
la 4,message1len # pocet znaku, ktere se maji vytisknout
svc 0 # volani Linuxoveho kernelu
# precteni vstupu od uzivatele
la 1,sys_read # cislo syscallu pro funkci "read"
la 2,std_input # standardni vstup
l 3,.LC3-.LT0(13) # adresa bufferu
la 4,50 # maximalni delka zpravy
svc 0 # volani Linuxoveho kernelu
# tisk druhe zpravy (zacatek odpovedi)
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,std_output # standardni vystup
l 3,.LC2-.LT0(13) # adresa retezce, ktery se ma vytisknout
la 4,message2len # pocet znaku, ktere se maji vytisknout
svc 0 # volani Linuxoveho kernelu
# tisk vstupu od uzivatele
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,std_output # standardni vystup
l 3,.LC3-.LT0(13) # adresa bufferu
la 4,50 # delka (max delka)
svc 0 # volani Linuxoveho kernelu
la 1,sys_exit # cislo sycallu pro funkci "exit"
la 2,0 # exit code = 0
svc 0 # volani Linuxoveho kernelu
# literal pool
.LT0:
.LC1: .long message1
.LC2: .long message2
.LC3: .long input
Překlad proběhne stejným způsobem, jaký již známe z předchozích dílů:
as -m31 read_input-s390.s -o read_input-s390.o ld -melf_s390 -s read_input-s390.o
(povšimněte si nutnosti použití přepínače -m31, určující mj. i použití 31bitových adres)
5. Druhá konverze programu, tentokrát pro architekturu s/390x
Verze pro 64bitovou architekturu s/390x, kterou taktéž naprogramoval Dan Horák, se již prakticky nijak neliší od „intelácké“ varianty, samozřejmě pokud vezmeme v úvahu rozdílnou instrukční sadu a jinak pojmenované registry (viz též vizuální porovnání na konci této kapitoly):
# asmsyntax=as
# Aplikace pro precteni dat ze standardniho vstupu
# naprogramovana v assembleru GNU as.
#
# Autor: Pavel Tisnovsky
# Dan Horák
# Linux kernel system call table
sys_exit = 1
sys_read = 3
sys_write = 4
# Dalsi konstanty pouzite v programu - standardni streamy
std_input = 0
std_output = 1
#-----------------------------------------------------------------------------
.section .data
message1:
.ascii "Enter your name: " # string, ktery NENI ukoncen nulou
message1len = . - message1 # delka prvni zpravy
.align 2 # musime zajistit zarovnani pro instrukci larl
message2:
.ascii "Hello " # string, ktery NENI ukoncen nulou
message2len = . - message2 # delka druhe zpravy
#-----------------------------------------------------------------------------
.section .bss
.lcomm input, 50 # rezervace 50 bajtu pro vstup
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
# tisk prvni zpravy (vyzvy)
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,std_output # standardni vystup
larl 3,message1 # adresa retezce, ktery se ma vytisknout
la 4,message1len # pocet znaku, ktere se maji vytisknout
svc 0 # volani Linuxoveho kernelu
# precteni vstupu od uzivatele
la 1,sys_read # cislo syscallu pro funkci "read"
la 2,std_input # standardni vstup
larl 3,input # adresa bufferu
la 4,50 # maximalni delka zpravy
svc 0 # volani Linuxoveho kernelu
# tisk druhe zpravy (zacatek odpovedi)
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,std_output # standardni vystup
larl 3,message2 # adresa retezce, ktery se ma vytisknout
la 4,message2len # pocet znaku, ktere se maji vytisknout
svc 0 # volani Linuxoveho kernelu
# tisk vstupu od uzivatele
la 1,sys_write # cislo syscallu pro funkci "write"
la 2,std_output # standardni vystup
larl 3,input # adresa bufferu
la 4,50 # delka (max delka)
svc 0 # volani Linuxoveho kernelu
la 1,sys_exit # cislo sycallu pro funkci "exit"
la 2,0 # exit code = 0
svc 0 # volani Linuxoveho kernelu
Překlad pro architekturu s/390x zařídí tyto dva příkazy:
as read_input-s390x.s -o read_input-s390x.o ld -s read_input-s390x.o
Pro ilustraci se podívejme na rozdíl mezi variantou pro procesory Intel a s/390x:
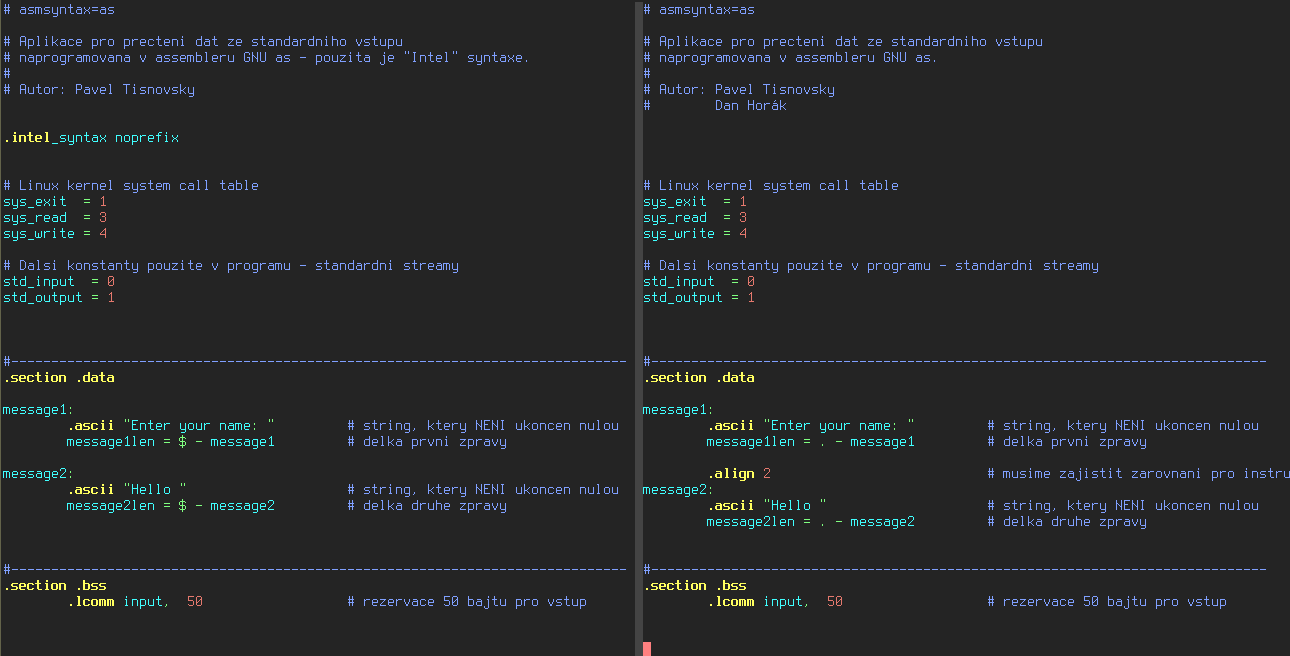
Obrázek 3: Rozdíl mezi variantou programu pro architekturu i386/x86-64 a s/390x (deklarace).
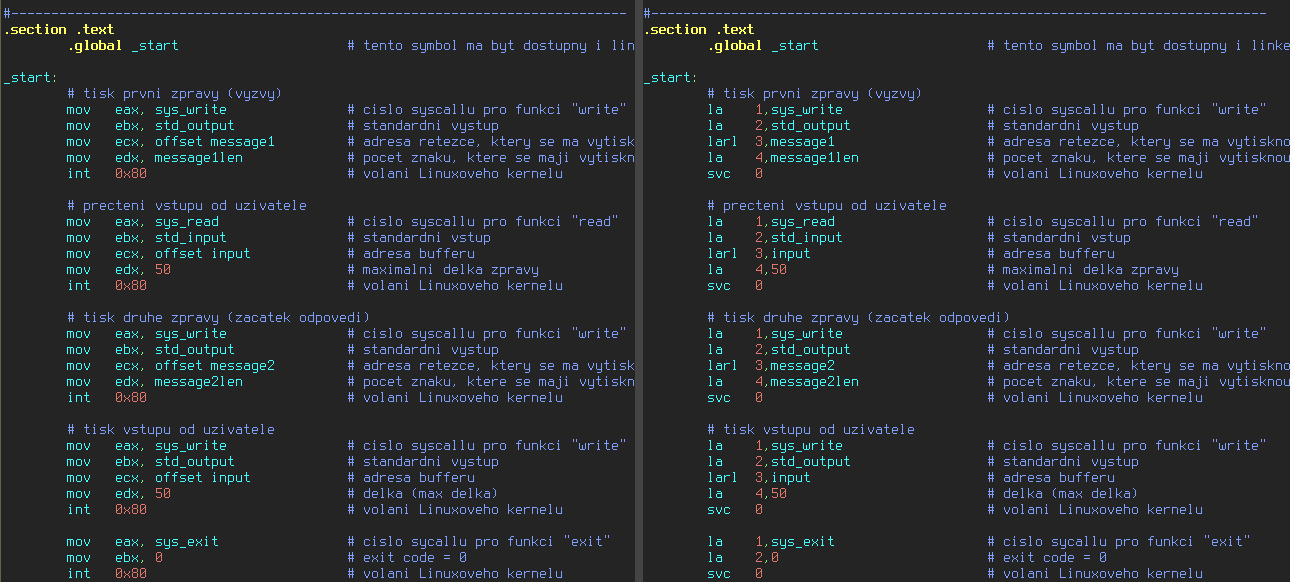
Obrázek 4: Rozdíl mezi variantou programu pro architekturu i386/x86-64 a s/390x (vlastní instrukce).
6. Konverze programu pro architekturu ARM
Další konverze zdrojového kódu určeného původně pro architekturu i386 bude provedena pro stále velmi populární 32bitovou architekturu ARM, tj. například pro oblíbené jednodeskové mikropočítače Raspberry Pi. Ve zdrojovém kódu si povšimněte několika změn, především použití znaku . (tečka) namísto $ (dolar) pro vyjádření aktuální adresy. Dále se odlišně zapisují komentáře, a to s využitím zavináče. Pro načtení adresy řetězce či bufferu se využívá instrukce ldr a namísto klíčového slova offset si v GNU Assembleru pro procesory ARM vystačíme se znakem = (rovná se), jehož přesný význam je vysvětlen v navazujícím textu. Podobně, jako je tomu u architektury s/390, i zde se pro zavolání služby jádra používá instrukce pojmenovaná svc (service). Výsledná podoba upraveného programu vypadá následovně:
# asmsyntax=as
# Aplikace pro precteni dat ze standardniho vstupu
# naprogramovana v assembleru GNU as - priklad pro ARM Thumb
#
# Autor: Pavel Tisnovsky
# Linux kernel system call table
sys_exit = 1
sys_read = 3
sys_write = 4
# Dalsi konstanty pouzite v programu - standardni streamy
std_input = 0
std_output = 1
#-----------------------------------------------------------------------------
.section .data
message1:
.ascii "Enter your name: " @ string, ktery NENI ukoncen nulou
message1len = . - message1 @ delka prvni zpravy
message2:
.ascii "Hello " @ string, ktery NENI ukoncen nulou
message2len = . - message2 @ delka druhe zpravy
#-----------------------------------------------------------------------------
.section .bss
.lcomm input, 50 @ rezervace 50 bajtu pro vstup
#-----------------------------------------------------------------------------
.section .text
.global _start @ tento symbol ma byt dostupny i z linkeru
_start:
@ tisk prvni zpravy (vyzvy)
mov r7, $sys_write @ cislo syscallu pro funkci "write"
mov r0, $std_output @ standardni vystup
ldr r1, =message1 @ adresa retezce, ktery se ma vytisknout
mov r2, $message1len @ pocet znaku, ktere se maji vytisknout
svc 0 @ volani Linuxoveho kernelu
@ precteni vstupu od uzivatele
mov r7, $sys_read @ cislo syscallu pro funkci "read"
mov r0, $std_input @ standardni vstup
ldr r1, =input @ adresa bufferu
mov r2, $50 @ maximalni delka zpravy
svc 0 @ volani Linuxoveho kernelu
@ tisk druhe zpravy (zacatek odpovedi)
mov r7, $sys_write @ cislo syscallu pro funkci "write"
mov r0, $std_output @ standardni vystup
ldr r1, =message2 @ adresa retezce, ktery se ma vytisknout
mov r2, $message2len @ pocet znaku, ktere se maji vytisknout
svc 0 @ volani Linuxoveho kernelu
@ tisk vstupu od uzivatele
mov r7, $sys_write @ cislo syscallu pro funkci "write"
mov r0, $std_output @ standardni vystup
ldr r1, =input @ adresa bufferu
mov r2, $50 @ delka (max delka)
svc 0 @ volani Linuxoveho kernelu
mov r7, $sys_exit @ cislo sycallu pro funkci "exit"
mov r0, #0 @ exit code = 0
svc 0 @ volani Linuxoveho kernelu
Překlad pro 32bitovou architekturu ARM zařídí tyto dva příkazy (spuštěné například na Raspberry Pi atd.):
as read_input-arm.s -o read_input-arm.o ld -s read_input-arm.o
Pro ilustraci se podívejme na rozdíl mezi variantou pro procesory Intel a 32bitové procesory ARM:

Obrázek 5: Rozdíl mezi variantou programu pro architekturu i386/x86-64 a ARM (deklarace).
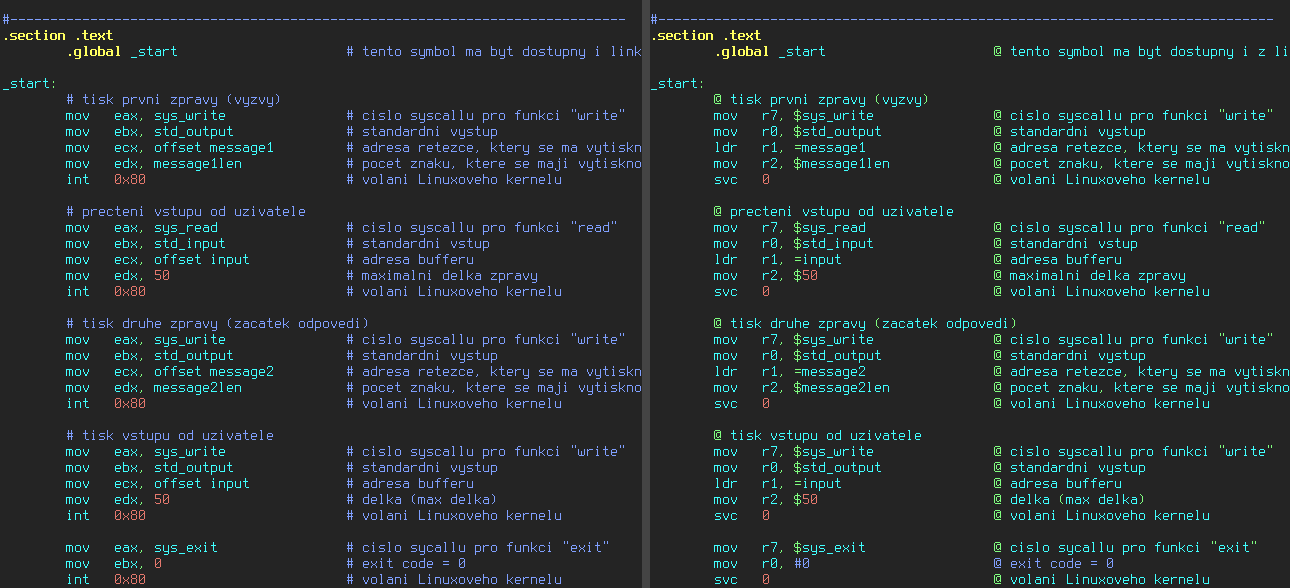
Obrázek 6: Rozdíl mezi variantou programu pro architekturu i386/x86-64 a ARM (vlastní instrukce).
7. Specifika původní instrukční sady ARM a způsob řešení adresování v assembleru
Podívejme se nyní na zpětný překlad (disassembling) strojového kódu pro 32bitové procesory ARM. Použijeme tento příkaz:
objdump -f -d -t -h a.out
a.out: file format elf32-littlearm
architecture: armv4, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00008074
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000068 00008074 00008074 00000074 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000017 000100dc 000100dc 000000dc 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000038 000100f8 000100f8 000000f3 2**3
ALLOC
3 .ARM.attributes 00000014 00000000 00000000 000000f3 2**0
CONTENTS, READONLY
SYMBOL TABLE:
no symbols
Disassembly of section .text:
00008074 <.text>:
8074: e3a07004 mov r7, #4
8078: e3a00001 mov r0, #1
807c: e59f104c ldr r1, [pc, #76] ; 0x80d0
8080: e3a02011 mov r2, #17
8084: ef000000 svc 0x00000000
8088: e3a07003 mov r7, #3
808c: e3a00000 mov r0, #0
8090: e59f103c ldr r1, [pc, #60] ; 0x80d4
8094: e3a02032 mov r2, #50 ; 0x32
8098: ef000000 svc 0x00000000
809c: e3a07004 mov r7, #4
80a0: e3a00001 mov r0, #1
80a4: e59f102c ldr r1, [pc, #44] ; 0x80d8
80a8: e3a02006 mov r2, #6
80ac: ef000000 svc 0x00000000
80b0: e3a07004 mov r7, #4
80b4: e3a00001 mov r0, #1
80b8: e59f1014 ldr r1, [pc, #20] ; 0x80d4
80bc: e3a02032 mov r2, #50 ; 0x32
80c0: ef000000 svc 0x00000000
80c4: e3a07001 mov r7, #1
80c8: e3a00000 mov r0, #0
80cc: ef000000 svc 0x00000000
80d0: 000100dc ldrdeq r0, [r1], -ip
80d4: 000100f8 strdeq r0, [r1], -r8
80d8: 000100ed andeq r0, r1, sp, ror #1
Na výpisu si povšimněte dvou faktů:
- Všechny instrukce mají konstantní šířku čtyř bajtů (32 bitů), bez ohledu na typ instrukce (typická RISCová architektura).
- Na samotném konci programu se zdánlivě nachází tři nové „instrukce“, které v původním kódu nejsou obsaženy.
Oba dva fakty spolu souvisí:
Kvůli konstantní šířce všech instrukcí může být problematické uložení konstanty či adresy do některého pracovního registru. Problém je to logický a vlastně shodný pro všechny „klasické“ RISCové mikroprocesory: šířka pracovních registrů je 32 bitů a současně je šířka instrukcí taktéž 32 bitů, tudíž není možné, aby se v instrukci vedle operačního kódu nacházela i 32 bitová konstanta. Tvůrci dalších RISCových mikroprocesorů se s touto problematikou snažili vypořádat různým způsobem, například zavedli speciální instrukci pro naplnění horních šestnácti bitů registru, zatímco pro naplnění spodních šestnácti bitů bylo možné použít například instrukci ADD s konstantou a nulovým registrem R0 (zhruba takovýmto způsobem je tato problematika řešena na mikroprocesorech MIPS). U mikroprocesorů ARM se zdá, že jeho konstruktéři nechtěli „obětovat“ další tranzistory na podobné typy instrukcí, takže se pro načtení konstanty používá dvojice instrukcí se stejným formátem, jako mají ostatní aritmetické a logické instrukce:
| # | Instrukce | Význam |
|---|---|---|
| 1 | MOV | načtení osmibitové konstanty 0..255 |
| 2 | MVN | načtení osmibitové konstanty s negací -1..-256 |
To je samozřejmě pro mnoho účelů zcela nedostatečné, ovšem ve skutečnosti je možné tuto konstantu pomocí barrel shifteru posunout o sudý počet míst 0, 2, 4, .. 30, takže se ve skutečnosti celkový počet konstant zvyšuje na hodnotu 8192 z celkového množství kombinací 232. Aby programátoři mohli relativně snadno načíst libovolnou konstantu do zvoleného registru, nabízí většina assemblerů pro mikroprocesory ARM pseudoinstrukci LDR ve tvaru:
LDR Rx, =konstanta
Podle hodnoty použité konstanty se tato instrukce buď převede na instrukci MOV, alternativně MVN, nebo na instrukci LDR načítající konstantu uloženou někde v programovém kódu (například za tělem subrutiny, kde lze vyhradit prostor pomocí direktivy LTORG). Tato konstanta je potom adresována relativně k hodnotě registru PC, pouze je nutné dát pozor na to, že offset pro relativní adresování má pouze dvanáct bitů, takže tato konstanta nemůže být uložena příliš „daleko“ (na to ostatně upozorní assembler).
8. Výsledná podoba přeloženého binárního kódu pro ARM
Zkusme si nyní provést zpětný překlad (disassembling), ovšem s kódem, v němž zůstaly uloženy ladicí informace (při překladu i linkování se použit přepínač -g). Výsledek vypadá následovně:
a.out: file format elf32-littlearm
architecture: armv4, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x00008074
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000068 00008074 00008074 00000074 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000017 000100dc 000100dc 000000dc 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000038 000100f8 000100f8 000000f3 2**3
ALLOC
3 .ARM.attributes 00000014 00000000 00000000 000000f3 2**0
CONTENTS, READONLY
4 .debug_aranges 00000020 00000000 00000000 00000108 2**3
CONTENTS, READONLY, DEBUGGING
5 .debug_info 00000072 00000000 00000000 00000128 2**0
CONTENTS, READONLY, DEBUGGING
6 .debug_abbrev 00000014 00000000 00000000 0000019a 2**0
CONTENTS, READONLY, DEBUGGING
7 .debug_line 0000005b 00000000 00000000 000001ae 2**0
CONTENTS, READONLY, DEBUGGING
SYMBOL TABLE:
00008074 l d .text 00000000 .text
000100dc l d .data 00000000 .data
000100f8 l d .bss 00000000 .bss
00000000 l d .ARM.attributes 00000000 .ARM.attributes
00000000 l d .debug_aranges 00000000 .debug_aranges
00000000 l d .debug_info 00000000 .debug_info
00000000 l d .debug_abbrev 00000000 .debug_abbrev
00000000 l d .debug_line 00000000 .debug_line
00000000 l df *ABS* 00000000 read_input-arm.o
00000001 l *ABS* 00000000 sys_exit
00000003 l *ABS* 00000000 sys_read
00000004 l *ABS* 00000000 sys_write
00000000 l *ABS* 00000000 std_input
00000001 l *ABS* 00000000 std_output
000100dc l .data 00000000 message1
00000011 l *ABS* 00000000 message1len
000100ed l .data 00000000 message2
00000006 l *ABS* 00000000 message2len
000100f8 l O .bss 00000032 input
00010130 g .bss 00000000 _bss_end__
000100f3 g .bss 00000000 __bss_start__
00010130 g .bss 00000000 __bss_end__
00008074 g .text 00000000 _start
000100f3 g .bss 00000000 __bss_start
00010130 g .bss 00000000 __end__
000100f3 g .data 00000000 _edata
00010130 g .bss 00000000 _end
Disassembly of section .text:
00008074 <_start>:
8074: e3a07004 mov r7, #4
8078: e3a00001 mov r0, #1
807c: e59f104c ldr r1, [pc, #76] ; 80d0 <_start+0x5c>
8080: e3a02011 mov r2, #17
8084: ef000000 svc 0x00000000
8088: e3a07003 mov r7, #3
808c: e3a00000 mov r0, #0
8090: e59f103c ldr r1, [pc, #60] ; 80d4 <_start+0x60>
8094: e3a02032 mov r2, #50 ; 0x32
8098: ef000000 svc 0x00000000
809c: e3a07004 mov r7, #4
80a0: e3a00001 mov r0, #1
80a4: e59f102c ldr r1, [pc, #44] ; 80d8 <_start+0x64>
80a8: e3a02006 mov r2, #6
80ac: ef000000 svc 0x00000000
80b0: e3a07004 mov r7, #4
80b4: e3a00001 mov r0, #1
80b8: e59f1014 ldr r1, [pc, #20] ; 80d4 <_start+0x60>
80bc: e3a02032 mov r2, #50 ; 0x32
80c0: ef000000 svc 0x00000000
80c4: e3a07001 mov r7, #1
80c8: e3a00000 mov r0, #0
80cc: ef000000 svc 0x00000000
80d0: 000100dc .word 0x000100dc
80d4: 000100f8 .word 0x000100f8
80d8: 000100ed .word 0x000100ed
Povšimněte si, že nyní jsou poslední tři 32bitová slova korektně rozpoznána jako 32bitové konstanty (adresy řetězců a bufferu) a taktéž toho, že u instrukcí ldr je nyní přímo uvedeno, že se (relativně) adresují právě tyto konstanty. Načtení je tedy nepřímé – z adresy řekněme PC+0x60 (absolutně 0x80d4) je načtena 32bitová konstanta chápaná jako adresa řetězce či bufferu.
9. Přepis programu pro čtení vstupu od uživatele do syntaxe NASMu
Před dalšími úpravami a otestováním programu na platformě Intel (architektury i386 a x86_64) provedeme přepis celého programu do syntaxe kompatibilní s Netwide Assemblerem (NASM). Již z předchozího dílu víme, že samotný zápis je sice v mnoha ohledech odlišný (jiný formát komentářů či zápisů konstant, zjednodušení při práci s adresami), ovšem základní koncepty zůstávají (a musí zůstat) zachovány. Odlišnosti najdeme například v pojmenování konstant (equ), v adresování (není nutné používat slovo offset), v alokaci bufferu v sekci .bss pomocí pseudooperace resb (reserve bytes) a v jiném znaku určeném pro zápis jednořádkových komentářů:
; asmsyntax=nasm
; Aplikace pro precteni dat ze standardniho vstupu.
;
; Autor: Pavel Tisnovsky
; Linux kernel system call table
sys_exit equ 1
sys_read equ 3
sys_write equ 4
; Dalsi konstanty pouzite v programu - standardni streamy
std_input equ 0
std_output equ 1
;-----------------------------------------------------------------------------
section .data
message1: db 'Enter your name: '
message1len equ $-message1 ; delka prvni zpravy
message2: db 'Hello '
message2len equ $-message2 ; delka druhe zpravy
;-----------------------------------------------------------------------------
section .bss
input resb 50 ; rezervace 50 bajtu pro vstup
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
; tisk prvni zpravy (vyzvy uzivateli)
mov eax, sys_write ; cislo syscallu pro funkci "write"
mov ebx, std_output ; standardni vystup
mov ecx, message1 ; adresa retezce, ktery se ma vytisknout
mov edx, message1len ; pocet znaku, ktere se maji vytisknout
int 80h ; volani Linuxoveho kernelu
; precteni vstupu od uzivatele
mov eax, sys_read ; cislo syscallu pro funkci "read"
mov ebx, std_input ; standardni vstup
mov ecx, input ; adresa bufferu
mov edx, 50 ; maximalni delka zpravy
int 80h ; volani Linuxoveho kernelu
; tisk druhe zpravy (zacatek odpovedi)
mov eax, sys_write ; cislo syscallu pro funkci "write"
mov ebx, std_output ; standardni vystup
mov ecx, message2 ; adresa retezce, ktery se ma vytisknout
mov edx, message2len ; pocet znaku, ktere se maji vytisknout
int 80h ; volani Linuxoveho kernelu
; tisk vstupu od uzivatele
mov eax, sys_write ; cislo syscallu pro funkci "write"
mov ebx, std_output ; standardni vystup
mov ecx, input ; adresa bufferu
mov edx, 50 ; delka (max delka)
int 80h ; volani Linuxoveho kernelu
mov eax, sys_exit ; cislo sycallu pro funkci "exit"
mov ebx, 0 ; exit code = 0
int 80h ; volani Linuxoveho kernelu
Překlad a slinkování do 32bitového kódu určeného pro procesory řady i386:
nasm -felf32 read_input_1.asm ld -s read_input_1.o
Překlad a slinkování do 64bitového kódu:
nasm -felf64 read_input_1.asm ld -s read_input_1.o
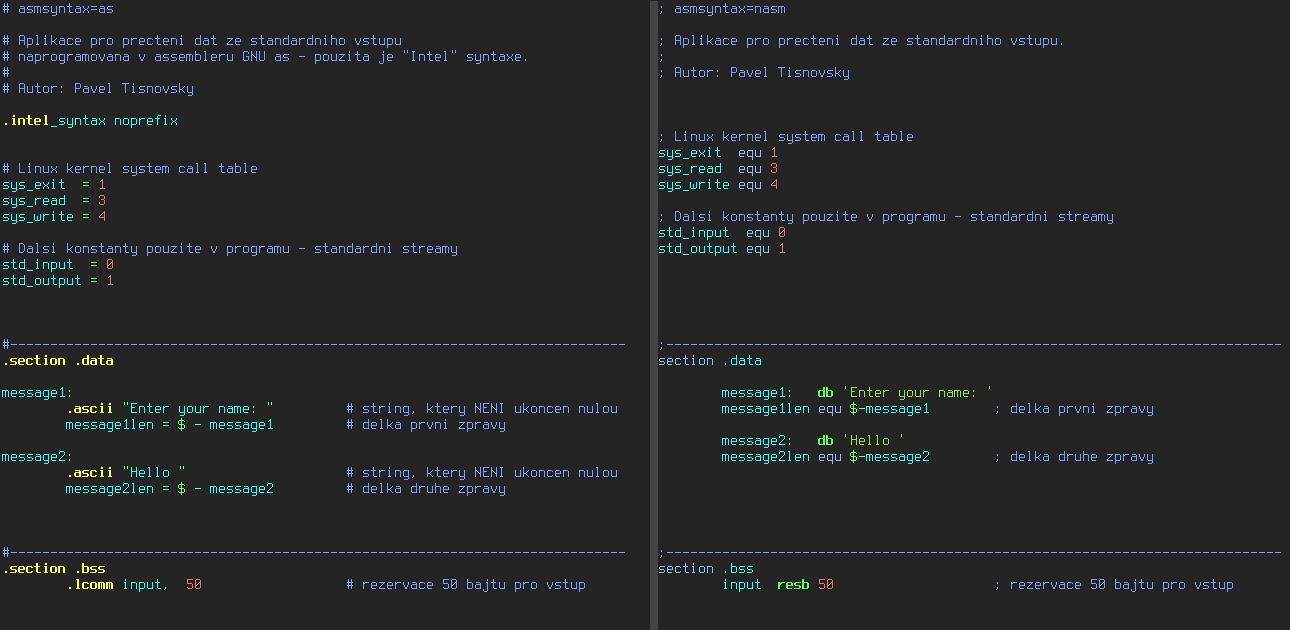
Obrázek 7: Rozdíl mezi variantou programu vytvořenou v GNU Assembleru s variantou určenou pro Netwide Assembler (deklarace).
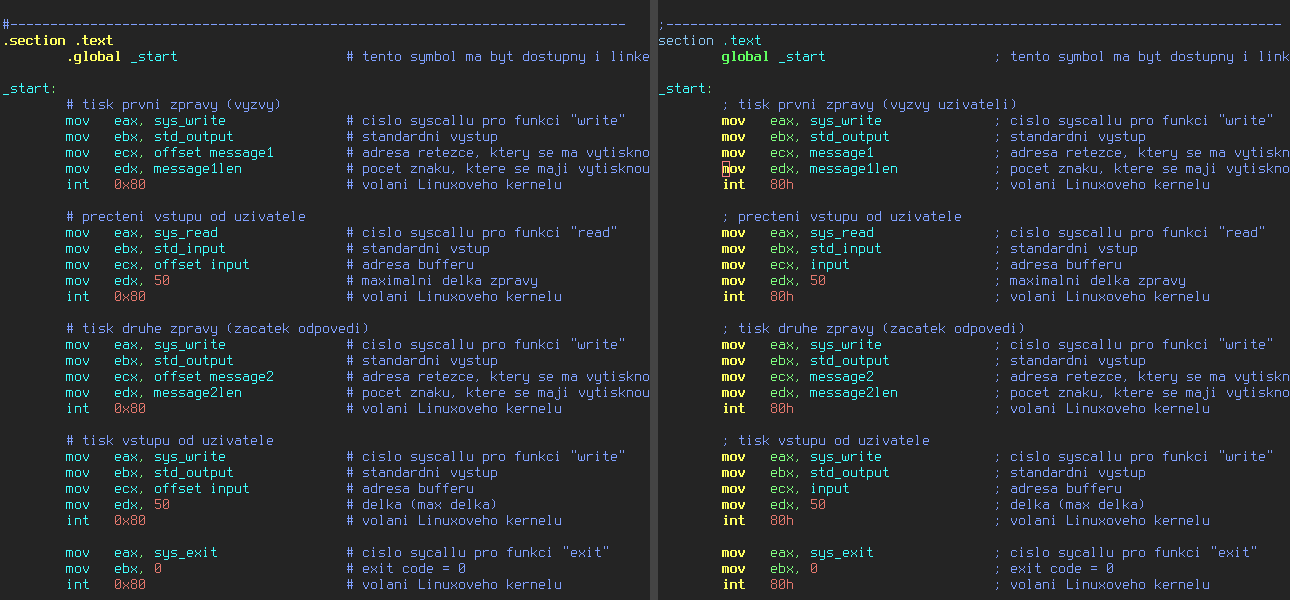
Obrázek 8: Rozdíl mezi variantou programu vytvořenou v GNU Assembleru s variantou určenou pro Netwide Assembler (vlastní instrukce).
10. Otestování programu a zjištění některých problémů
Pokud si jakýkoli z výše uvedených programů otestujeme, zjistíme, že nepracují zcela korektně. Zkusme otestování provést takto:
echo "test1" | ./a.out > check.txt echo "test2" | ./a.out >> check.txt echo "zprava, ktera musi byt delsi nez padesat znaku, predana programu" | ./a.out >> check.txt echo "zaverecny test" | ./a.out >> check.txt
Výsledný soubor si prohlédneme včetně všech skrytých znaků:
xxd -g1 check.txt
0000000: 45 6e 74 65 72 20 79 6f 75 72 20 6e 61 6d 65 3a Enter your name: 0000010: 20 48 65 6c 6c 6f 20 74 65 73 74 31 0a 00 00 00 Hello test1.... 0000020: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 0000030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 0000040: 00 00 00 00 00 00 00 00 00 45 6e 74 65 72 20 79 .........Enter y 0000050: 6f 75 72 20 6e 61 6d 65 3a 20 48 65 6c 6c 6f 20 our name: Hello 0000060: 74 65 73 74 32 0a 00 00 00 00 00 00 00 00 00 00 test2........... 0000070: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 0000080: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 0000090: 00 00 45 6e 74 65 72 20 79 6f 75 72 20 6e 61 6d ..Enter your nam 00000a0: 65 3a 20 48 65 6c 6c 6f 20 7a 70 72 61 76 61 2c e: Hello zprava, 00000b0: 20 6b 74 65 72 61 20 6d 75 73 69 20 62 79 74 20 ktera musi byt 00000c0: 64 65 6c 73 69 20 6e 65 7a 20 70 61 64 65 73 61 delsi nez padesa 00000d0: 74 20 7a 6e 61 6b 75 2c 20 70 72 45 6e 74 65 72 t znaku, prEnter 00000e0: 20 79 6f 75 72 20 6e 61 6d 65 3a 20 48 65 6c 6c your name: Hell 00000f0: 6f 20 7a 61 76 65 72 65 63 6e 79 20 74 65 73 74 o zaverecny test 0000100: 0a 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 0000110: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 0000120: 00 00 00 00 ....
Problém samozřejmě spočívá v tom, že si nikam nezapisujeme počet skutečně přečtených bajtů, takže se vytiskne vždy celý buffer, který obsahuje výplňové nuly. Způsob řešení tohoto problému si vysvětlíme příště.
11. Repositář s demonstračními příklady
Všechny dnes popisované demonstrační příklady byly společně s podpůrnými skripty uloženy do GIT repositáře dostupného na adrese https://github.com/tisnik/presentations/. Následuje tabulka s odkazy na zdrojové kódy příkladů i na již zmíněné podpůrné skripty:
Čtení vstupu od uživatel: verze pro i386, x86-64, s/390, s/390x a ARM s Thumb
Čtení vstupu od uživatele: první verze přepsaná do syntaxe NASMu
| # | Soubor | Popis | Odkaz do repositáře |
|---|---|---|---|
| 1 | read_input_1.asm | program pro NASM | https://github.com/tisnik/presentations/blob/master/assembler/08_nasm_read_input/read_input_1.asm |
| 2 | assemble_i386 | skript pro překlad na i386 | https://github.com/tisnik/presentations/blob/master/assembler/08_nasm_read_input/assemble_i386 |
| 3 | assemble_x86_64 | skript pro překlad na x86/64 | https://github.com/tisnik/presentations/blob/master/assembler/08_nasm_read_input/assemble_x86_64 |
| 4 | disassemble | skript pro disassembling | https://github.com/tisnik/presentations/blob/master/assembler/08_nasm_read_input/disassemble |
Čtení vstupu od uživatele: druhá verze pro lepší otestování chování programu
(podrobněji bude popsána příště)
| # | Soubor | Popis | Odkaz do repositáře |
|---|---|---|---|
| 1 | read_input_2.asm | program pro NASM | https://github.com/tisnik/presentations/blob/master/assembler/09_nasm_check_read_input/read_input_2.asm |
| 2 | assemble_i386 | skript pro překlad na i386 | https://github.com/tisnik/presentations/blob/master/assembler/09_nasm_check_read_input/assemble_i386 |
| 3 | assemble_x86_64 | skript pro překlad na x86/64 | https://github.com/tisnik/presentations/blob/master/assembler/09_nasm_check_read_input/assemble_x86_64 |
| 4 | disassemble | skript pro disassembling | https://github.com/tisnik/presentations/blob/master/assembler/09_nasm_check_read_input/disassemble |
| 5 | check | skript pro test funkčnosti | https://github.com/tisnik/presentations/blob/master/assembler/09_nasm_check_read_input/check |
| 6 | check.txt | výsledek testu | https://github.com/tisnik/presentations/blob/master/assembler/09_nasm_check_read_input/check.txt |
Čtení vstupu od uživatele: třetí verze se zapamatováním délky vstupního řetězce
(podrobněji bude popsána příště)
| # | Soubor | Popis | Odkaz do repositáře |
|---|---|---|---|
| 1 | read_input_3.asm | program pro NASM | https://github.com/tisnik/presentations/blob/master/assembler/10_nasm_better_read_input/read_input_3.asm |
| 2 | assemble_i386 | skript pro překlad na i386 | https://github.com/tisnik/presentations/blob/master/assembler/10_nasm_better_read_input/assemble_i386 |
| 3 | assemble_x86_64 | skript pro překlad na x86/64 | https://github.com/tisnik/presentations/blob/master/assembler/10_nasm_better_read_input/assemble_x86_64 |
| 4 | disassemble | skript pro disassembling | https://github.com/tisnik/presentations/blob/master/assembler/10_nasm_better_read_input/disassemble |
| 5 | check | skript pro test funkčnosti | https://github.com/tisnik/presentations/blob/master/assembler/10_nasm_better_read_input/check |
| 6 | check.txt | výsledek testu | https://github.com/tisnik/presentations/blob/master/assembler/10_nasm_better_read_input/check.txt |
12. Odkazy na Internetu
- Linux assemblers: A comparison of GAS and NASM
http://www.ibm.com/developerworks/library/l-gas-nasm/index.html - Programovani v assembleru na OS Linux
http://www.cs.vsb.cz/grygarek/asm/asmlinux.html - Is it worthwhile to learn x86 assembly language today?
https://www.quora.com/Is-it-worthwhile-to-learn-x86-assembly-language-today?share=1 - Why Learn Assembly Language?
http://www.codeproject.com/Articles/89460/Why-Learn-Assembly-Language - Is Assembly still relevant?
http://programmers.stackexchange.com/questions/95836/is-assembly-still-relevant - Why Learning Assembly Language Is Still a Good Idea
http://www.onlamp.com/pub/a/onlamp/2004/05/06/writegreatcode.html - Assembly language today
http://beust.com/weblog/2004/06/23/assembly-language-today/ - Assembler: Význam assembleru dnes
http://www.builder.cz/rubriky/assembler/vyznam-assembleru-dnes-155960cz - Assembler pod Linuxem
http://phoenix.inf.upol.cz/linux/prog/asm.html - AT&T Syntax versus Intel Syntax
https://www.sourceware.org/binutils/docs-2.12/as.info/i386-Syntax.html - Linux Assembly website
http://asm.sourceforge.net/ - Using Assembly Language in Linux
http://asm.sourceforge.net/articles/linasm.html - vasm
http://sun.hasenbraten.de/vasm/ - vasm – dokumentace
http://sun.hasenbraten.de/vasm/release/vasm.html - The Yasm Modular Assembler Project
http://yasm.tortall.net/ - 680x0:AsmOne
http://www.amigacoding.com/index.php/680x0:AsmOne - ASM-One Macro Assembler
http://en.wikipedia.org/wiki/ASM-One_Macro_Assembler - ASM-One pages
http://www.theflamearrows.info/documents/asmone.html - Základní informace o ASM-One
http://www.theflamearrows.info/documents/asminfo.html - Linux Syscall Reference
http://syscalls.kernelgrok.com/ - Programming from the Ground Up Book - Summary
http://savannah.nongnu.org/projects/pgubook/ - IBM System 360/370 Compiler and Historical Documentation
http://www.edelweb.fr/Simula/ - IBM 700/7000 series
http://en.wikipedia.org/wiki/IBM_700/7000_series - IBM System/360
http://en.wikipedia.org/wiki/IBM_System/360 - IBM System/370
http://en.wikipedia.org/wiki/IBM_System/370 - Mainframe family tree and chronology
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_FT1.html - 704 Data Processing System
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP704.html - 705 Data Processing System
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP705.html - The IBM 704
http://www.columbia.edu/acis/history/704.html - IBM Mainframe album
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_album.html - Osmibitové muzeum
http://osmi.tarbik.com/ - Tesla PMI-80
http://osmi.tarbik.com/cssr/pmi80.html - PMI-80
http://en.wikipedia.org/wiki/PMI-80 - PMI-80
http://www.old-computers.com/museum/computer.asp?st=1&c=1016
