
Ve druhé části článku o projektu Vrapper, který do integrovaného vývojového prostředí Eclipse přináší poměrně pokročilou emulaci funkcí Vimu, se seznámíme s některými dalšími důležitými vlastnostmi Vrapperu. Jedná se především o příkazy pro vyhledávání a nahrazování textu (substitute). Teprve s těmito funkcemi je možné možnosti Eclipse a Vrapperu využít skutečně naplno.
Obsah
1. Vrapper aneb spojení možností Vimu a Eclipse (část 2: vyhledávání a nahrazování textu)
2. Příkazy pro vyhledávání textu
3. Nalezení n-tého výskytu textu
4. Posun kurzoru po nalezení textu (přesun na jiný řádek či sloupec)
5. Význam konfiguračních voleb ignorecase a smartcase
6. Použití regulárních výrazů při vyhledávání
7. Příkaz pro vyhledání s nahrazením (substitute)
8. Specifikace rozsahu nahrazování
9. Rozsah nahrazování zadaný pomocí vyhledávacích příkazů
10. Význam některých přepínačů příkazu substitute
1. Vrapper aneb spojení možností Vimu a Eclipse (část 2: vyhledávání a nahrazování textu)
V úvodní části článku o projektu Vrapper, který do integrovaného vývojového prostředí Eclipse přidává emulaci chování populárního textového editoru Vim, jsme se seznámili s tím, jakým způsobem se Vrapper do Eclipse instaluje a jak se používá namísto výchozího programátorského editoru, jenž je standardní součástí Eclipse. Taktéž jsme si řekli, které vlastnosti Vimu jsou ve Vrapperu podporovány. Připomeňme si jen ve stručnosti, že je samozřejmě možné používat všechny základní režimy práce Vimu (normální, příkazový, vkládací, přepisovací, vizuální atd.), k dispozici jsou taktéž prakticky všechny editační příkazy a operátory (yank, delete, change, shift), příkaz pro vyhledávání a nahrazování textu, definovat je možné značky a používat lze i registry (přesněji řečeno alespoň většinu běžně používaných registrů).
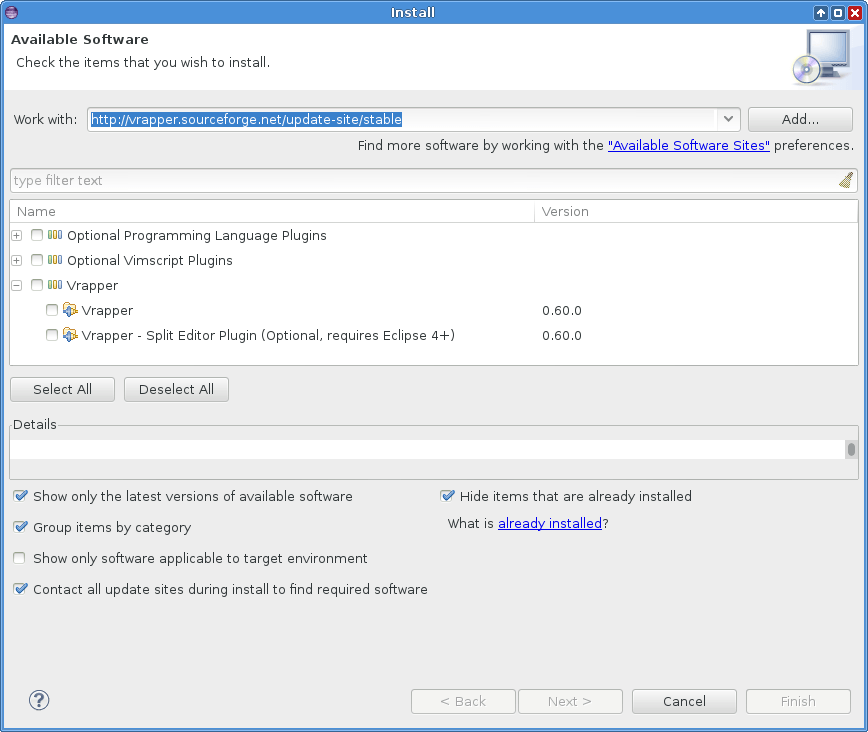
Obrázek 1: Průběh instalace pluginu Vrapper. Do tohoto dialogu je nutné zadat adresu (URL), na níž se nachází balíček Vrapper. Tato adresa zní http://vrapper.sourceforge.net/update-site/stable. Po potvrzení se objeví krátká zpráva „Pending“ a posléze by se měly vypsat všechny balíčky, které byly na uvedené adrese nalezeny.
Ve druhé a posléze i ve třetí části článku o přídavném modulu Vrapper si ukážeme některé pokročilejší možnosti, které tento plugin vývojářům i dalším uživatelům integrovaného vývojového prostředí Eclipse přináší. Nejdříve si podrobněji popíšeme dva základní příkazy pro práci s textem: jedná se o příkaz pro vyhledávání (stručně zmíněný již minule) a taktéž o příkaz pro vyhledávání se současným nahrazováním textu. Možnosti těchto dvou příkazů jsou velmi široké a to mj. i proto, že je možné použít regulární výrazy, o čemž se zmíníme v šesté kapitole a u příkazu substitute i oblast v dokumentu, kde se má vyhledávání a nahrazování provést.
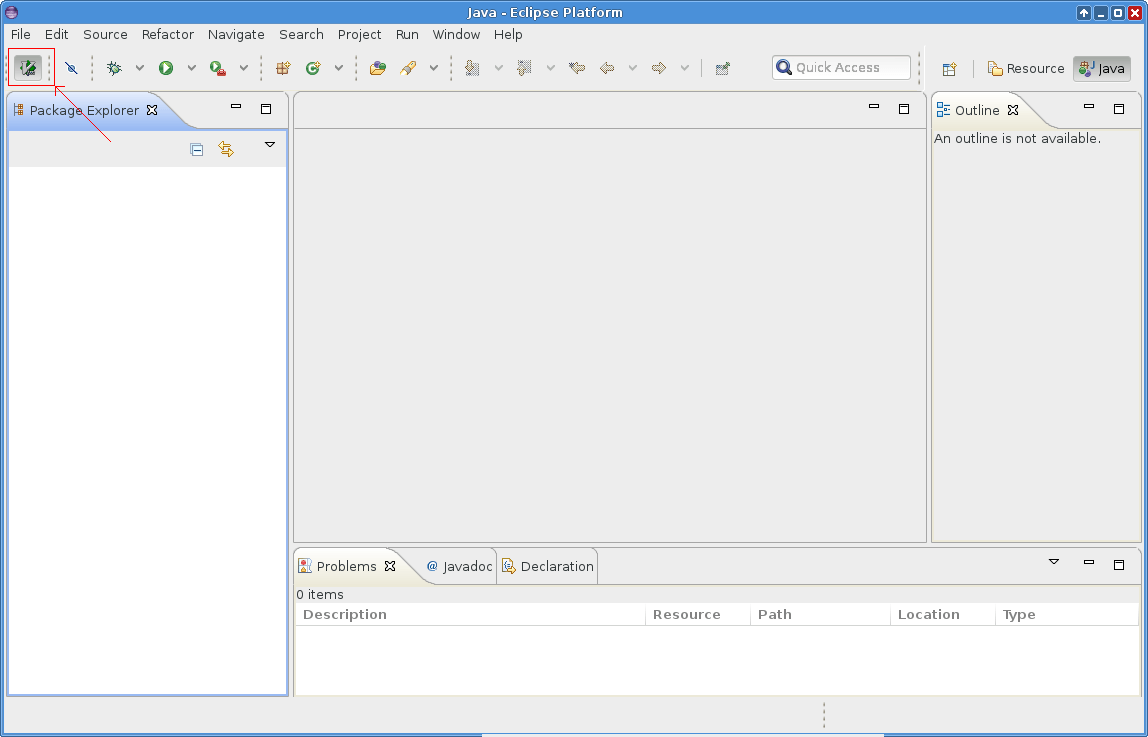
Obrázek 2: Pokud se v integrovaném vývojovém prostředí objevila tato ikona, podařilo se Vrapper korektně nainstalovat a následně inicializovat. Instalace je podrobněji popsána v první části tohoto článku.
2. Příkazy pro vyhledávání textu
Se základními příkazy sloužícími k vyhledávání textu (například ve zdrojových kódech) jsme se již seznámili minule. Připomeňme si tedy, že pro vyhledávání ve zdrojovém kódu se používají příkazy / a ?, přičemž první příkaz hledá směrem dolů (od aktuální pozice kurzoru směrem ke konci souboru), zatímco příkaz druhý naopak směrem k začátku zdrojového textu. Po zadání / či ? editor očekává regulární výraz ukončený klávesou Enter. Po vyhledání prvního výskytu textu odpovídajícího regulárnímu výrazu lze použít příkaz n pro nalezení dalšího výskytu či N pro nalezení výskytu předchozího (povšimněte si zde logiky: klávesa Shift vždy mění směr vyhledávání, minimálně na anglické klávesnici). Alternativně lze hledat výskyt jediného znaku příkazy f (find) a t (till), pro které opět existuje i verze hledající směrem zpět: F a T. Třetí možnost představují příkazy * a # určené pro hledání dalšího/předchozího identifikátoru, přičemž identifikátor se nachází pod kurzorem (tyto příkazy jsou velmi užitečné a vyplatí se je naučit používat, zejména při práci s rozsáhlejšími zdrojovými kódy).
Obrázek 3: Zvýraznění vyhledaných částí textu je možné ovlivnit volbami hlsearch a incsearch. Na tomto screenshotu jsou použity (zapnuty) obě volby.
3. Nalezení n-tého výskytu textu
Nyní se podrobněji zaměřme především na příkazy / a ? zmíněné již v předchozí kapitole. Tyto příkazy totiž umožňují, aby se k vyhledávanému textu popř. k regulárnímu výrazu přidaly i další nepovinné parametry ovlivňující vyhledávání. Před samotným příkazem se může – podobně jako je tomu u mnoha dalších příkazů – uvést nějaké číslo rozdílné od nuly (nula je totiž sama o sobě příkazem – skok na začátek řádku). Toto číslo má jednoduchý význam: při jeho použití se nevyhledá nejbližší text odpovídající zadanému regulárnímu výrazu, ale nalezne se až n-tý výskyt tohoto textu. Tato vlastnost se může použít například při tvorbě maker apod. Chování příkazu /, před nímž je zadáno nějaké kladné číslo, je ukázáno na následující trojici screenshotů:
Obrázek 4: Kurzor je před použitím příkazu / umístěn na začátek zdrojového souboru.
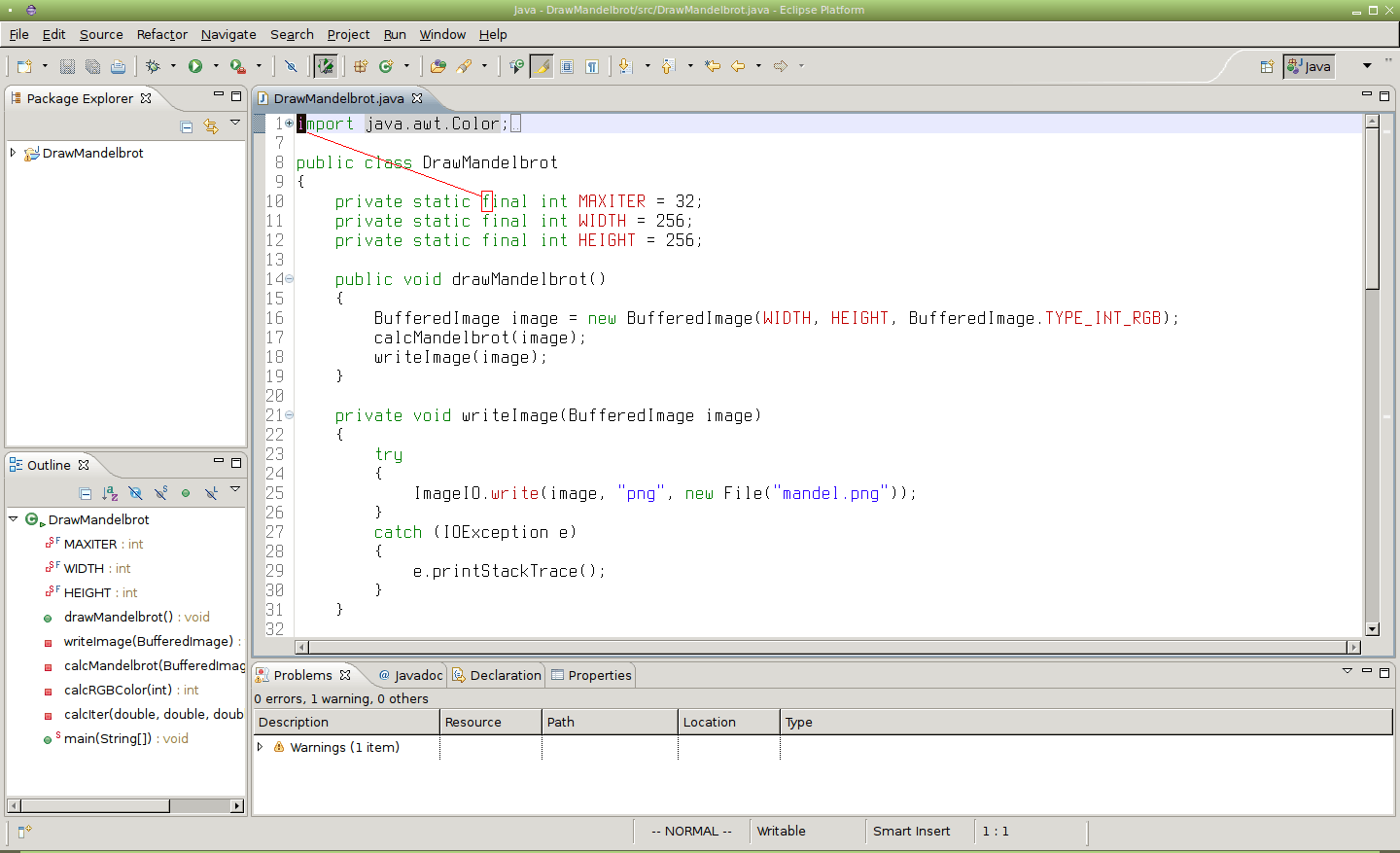
Obrázek 5: Po zadání příkazu /final[Enter] se kurzor přesune na místo označené červeným obdélníkem.
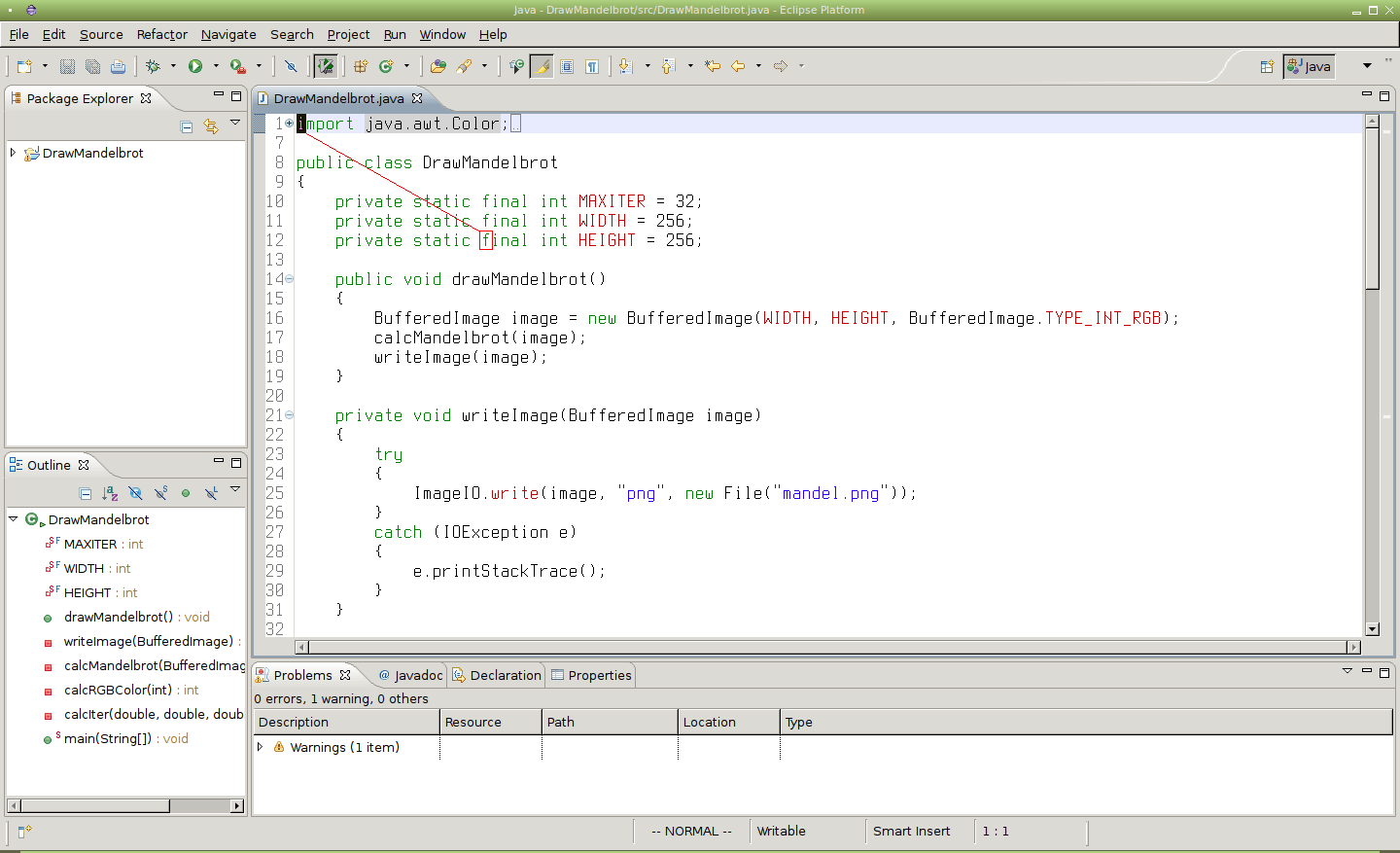
Obrázek 6: Pokud se namísto příkazu /final[Enter] použije 3/final[Enter], přesune se kurzor až na třetí výskyt slova „final“.
4. Posun kurzoru po nalezení textu (přesun na jiný řádek či sloupec)
Kromě přesunu kurzoru na první nalezený text popř. alternativně na n-tý nalezený text je možné specifikovat, kam přesně se má kurzor posunout relativně od nalezeného textu. Pokud se zadá vyhledávací příkaz ve stylu /text/číslo[Enter] či /text/+číslo[Enter], nalezne se odpovídající text a ihned poté se kurzor přesune o zadaný počet řádků níže. Podobně pro příkaz /text/-číslo[Enter] dojde k posunu na řádky umístěné nad nalezeným textem. Taktéž je možné použít /text/s+číslo[Enter] či /text/e+číslo[Enter] pro relativní posun přímo na řádku, kde byl text nalezen. Znak „s“ specifikuje začátek nalezeného textu (resp. relativní posun od začátku textu), zatímco znak „e“ konec nalezeného textu. Opět se podívejme na ilustrační screenshoty:

Obrázek 7: Před zadáním příkazu /final/10[Enter] se kurzor nachází na začátku zdrojového kódu.
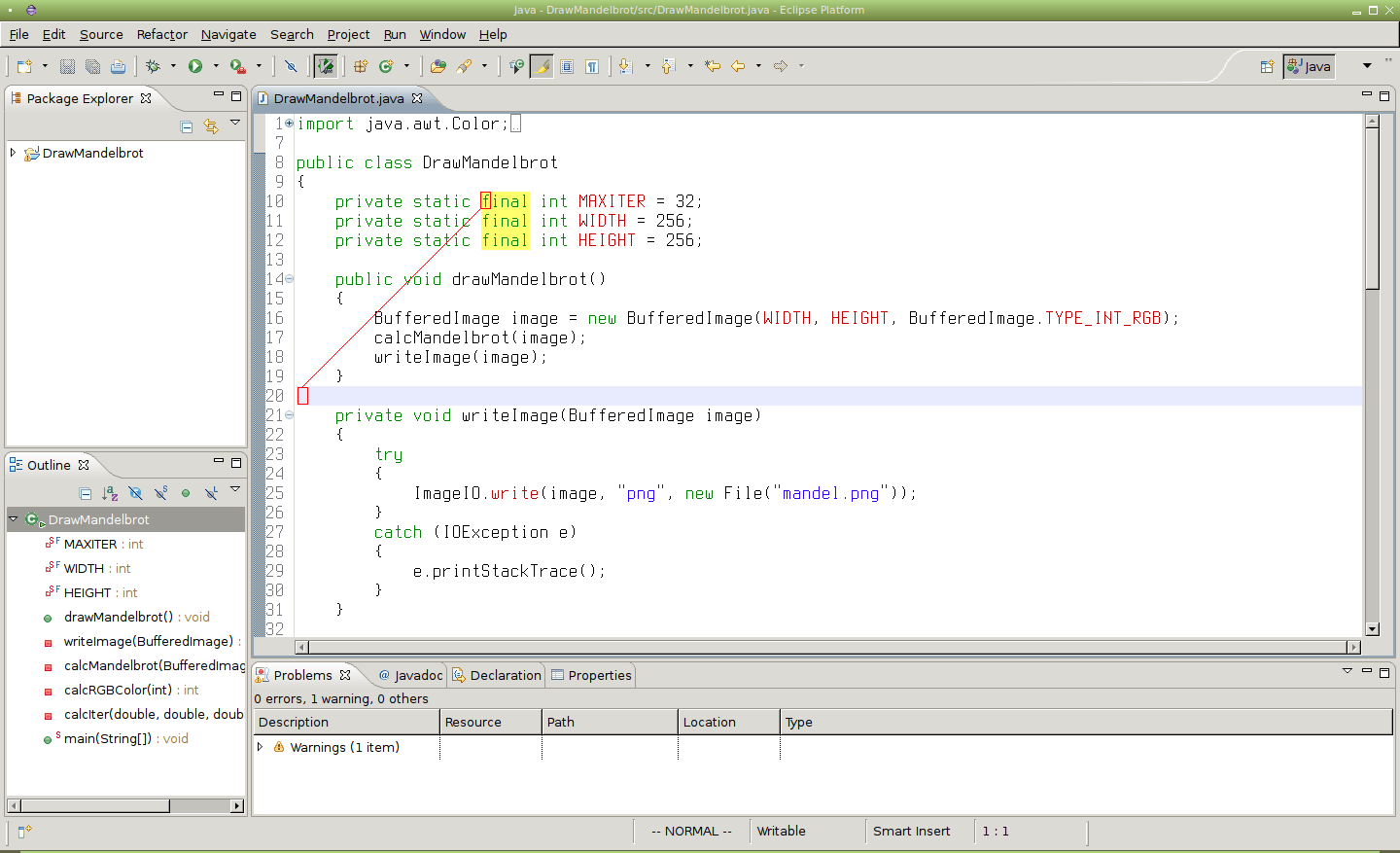
Obrázek 8: Po zadání příkazu /final/10[Enter] se kurzor přesune na desátý řádek pod první nalezené slovo „final“ (aktuální řádek je zvýrazněn podsvícením).
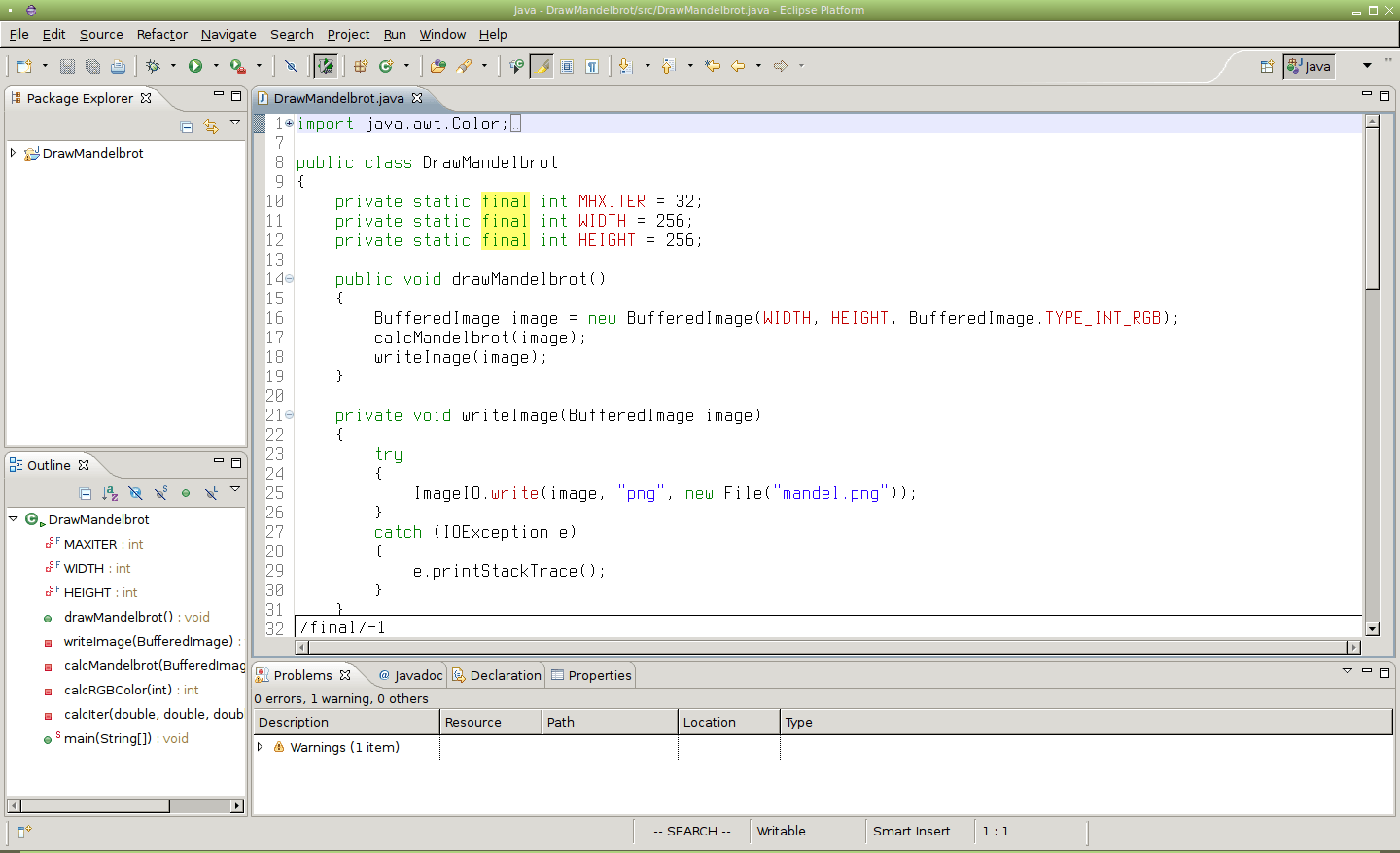
Obrázek 9: Před zadáním příkazu /final/-1[Enter] se kurzor opět nachází na začátku zdrojového kódu (shodná pozice, jako na obrázku číslo 7).
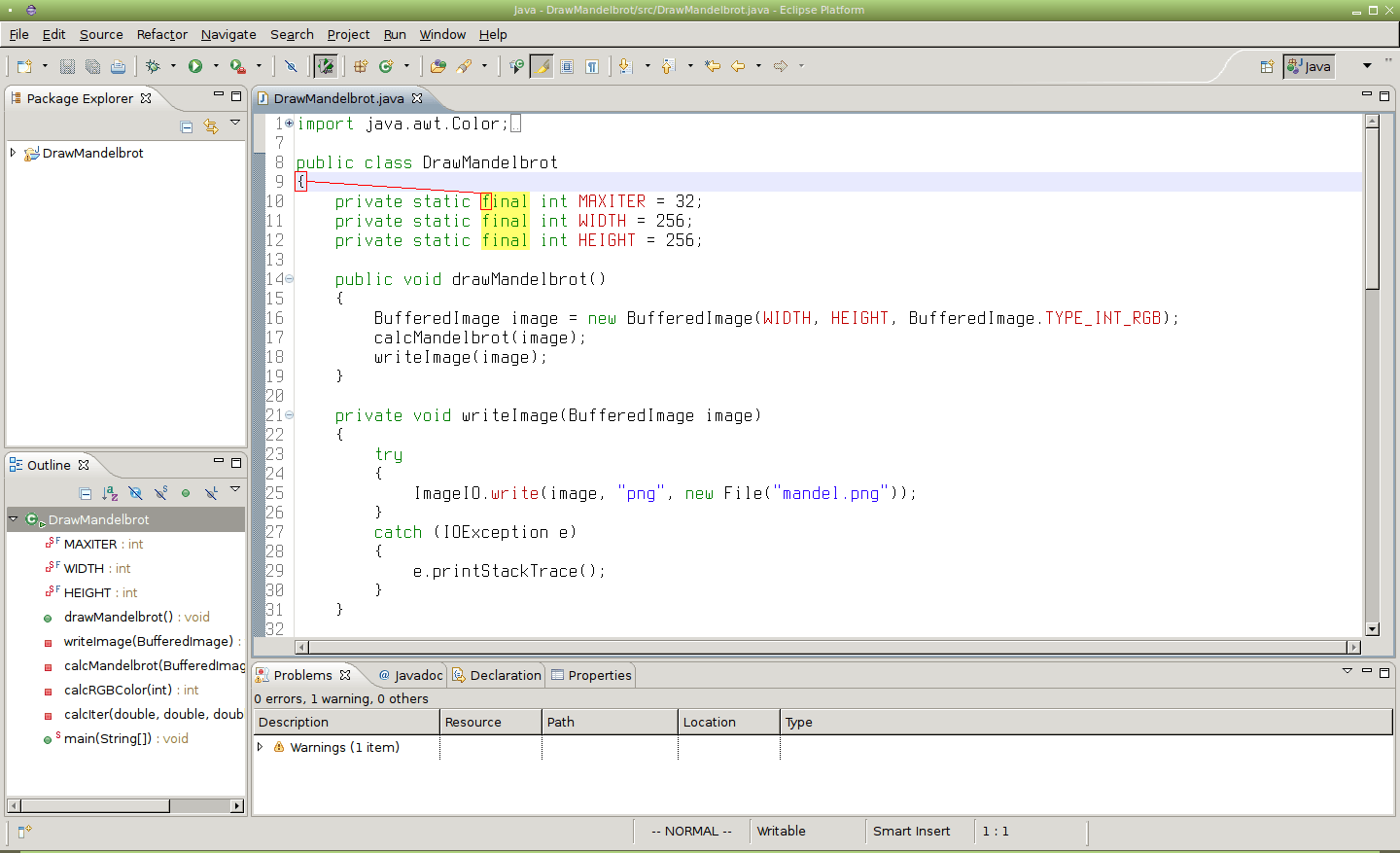
Obrázek 10: Po zadání příkazu /final/-1[Enter] se kurzor přesune na řádek před prvním výskytem slova „final“.
U příkazu ?text (hledání směrem k začátku souboru) je nutné dát pozor na to, že i druhý znak před číslem musí být otazník, tj. správná syntaxe je ?text?číslo[Enter]. Situace při použití příkazu ? vypadá takto:
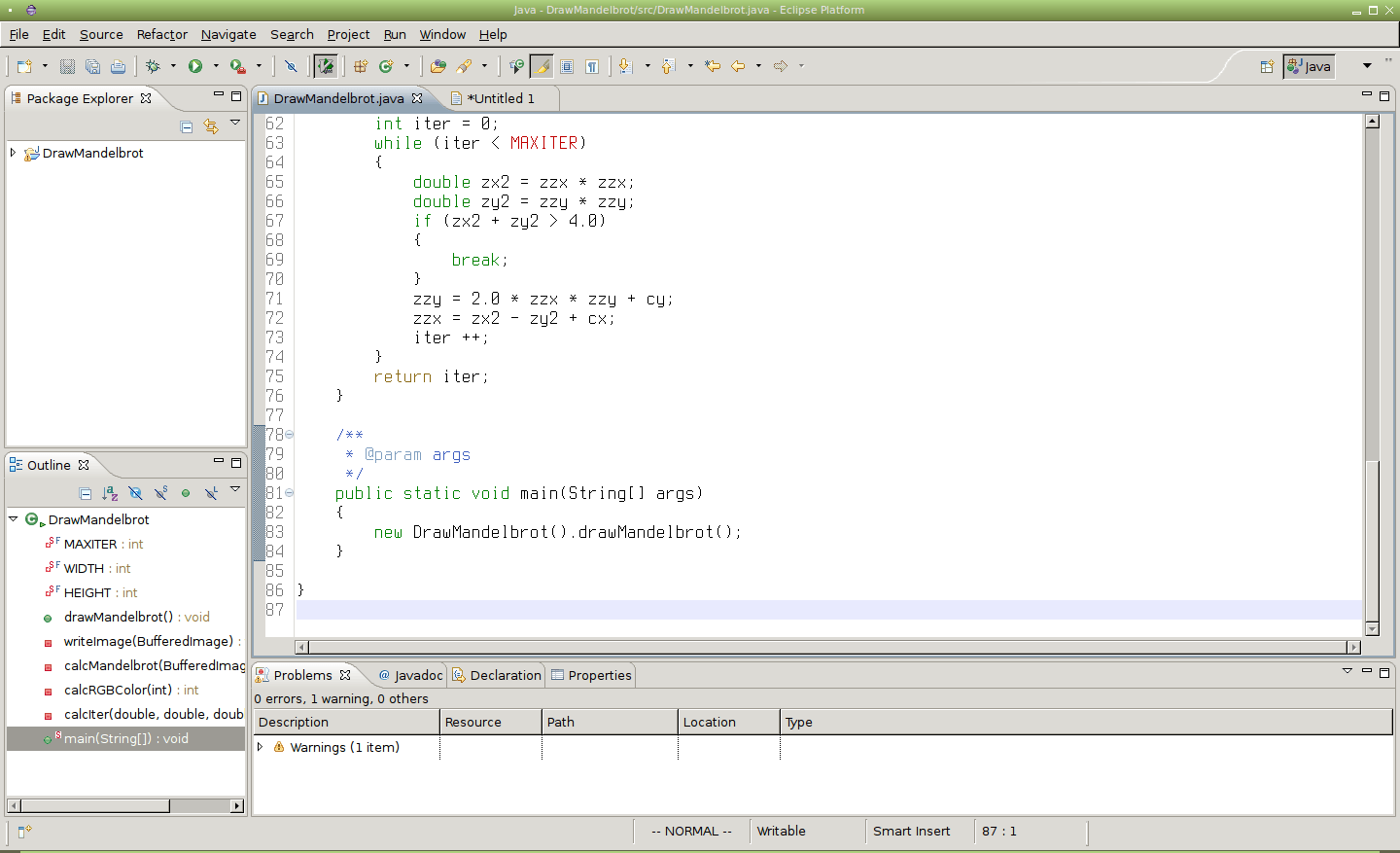
Obrázek 11: Před zadáním příkazu ?public?2[Enter] se kurzor nachází na konci zdrojového kódu.
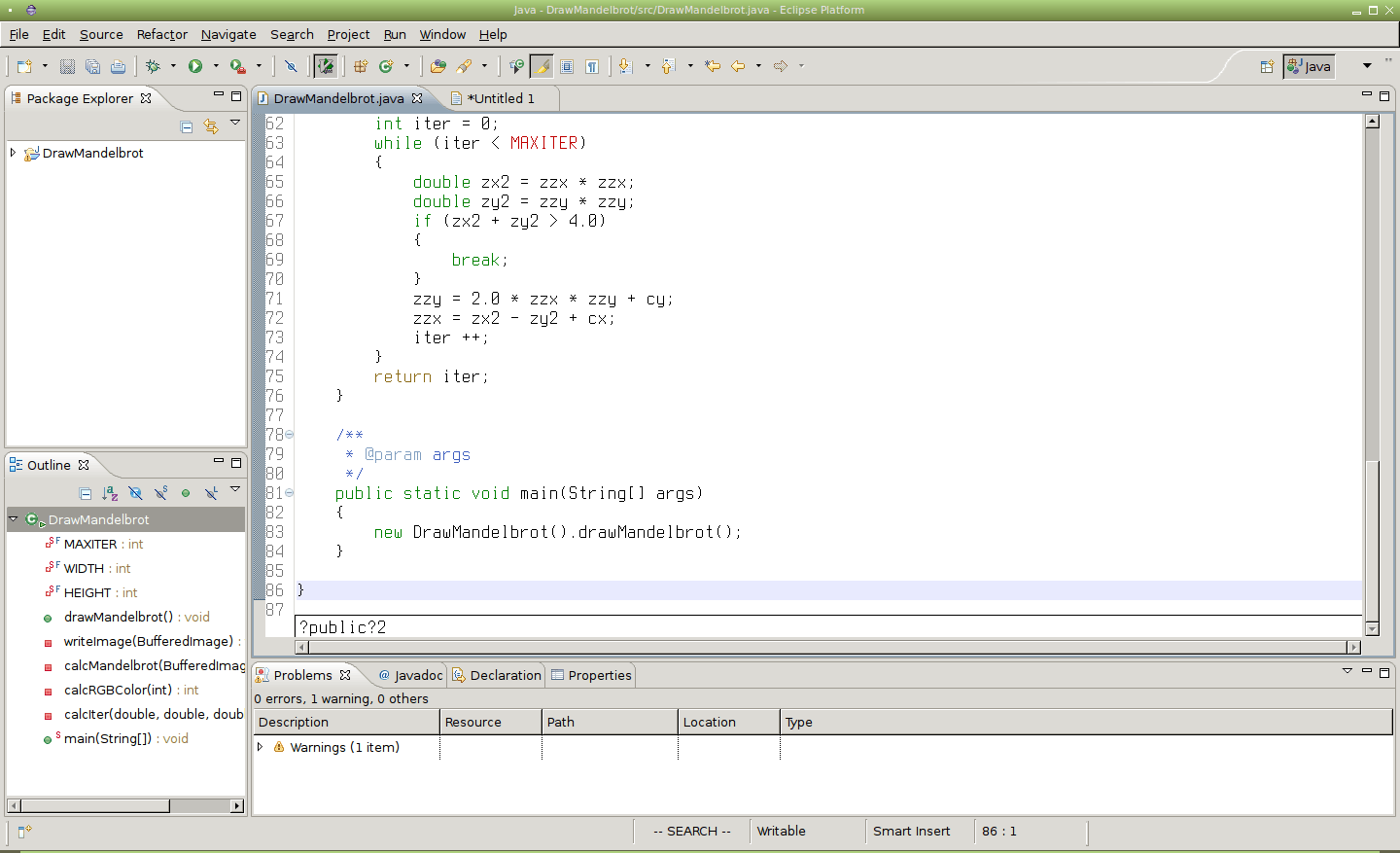
Obrázek 12: Průběh zadávání příkazu ?public?2[Enter].

Obrázek 13: Po zadání příkazu ?public?2[Enter] se sice vysvítí slovo „public“, ale kurzor se posune o dva řádky níže.
5. Význam konfiguračních voleb ignorecase a smartcase
Při vyhledávání ve zdrojových kódech (či v jiných textových souborech) s využitím příkazů / a ? lze specifikovat, zda se mají při vyhledávání rozlišovat malá a velká písmena, tj. zda se například při zadání příkazu /hello[Enter] nalezne i řetězec „Hello“ či nikoli. K nastavení této vlastnosti slouží konfigurační volby ignorecase a smartcase. Tyto volby jsou nastavovány příkazem :set a vzhledem k tomu, že se jedná o přepínač (pravdivostní hodnotu), jsou k dispozici následující možnosti, které je možné zadat v příkazovém režimu, tj. po stisku dvojtečky:
:set ignorecase :set noignorecase :set smartcase :set nosmartcase
Význam jednotlivých nastavení je následující:
| Volba | Stručný popis |
|---|---|
| ignorecase | při vyhledávání se bude ignorovat velikost písmen ve vyhledávaném textu |
| noignorecase | opak předchozí volby, velikost písmen se nebude ignorovat |
| smartcase | velikost písmen se bude ignorovat pouze ve chvíli, kdy má vyhledávaný text pouze malá písmena |
| nosmartcase | chování plně závisí na nastavení ignorecase/noignorecase |
V praxi tyto volby ovlivní vyhledávání způsobem, jenž je naznačen na následujících screenshotech:
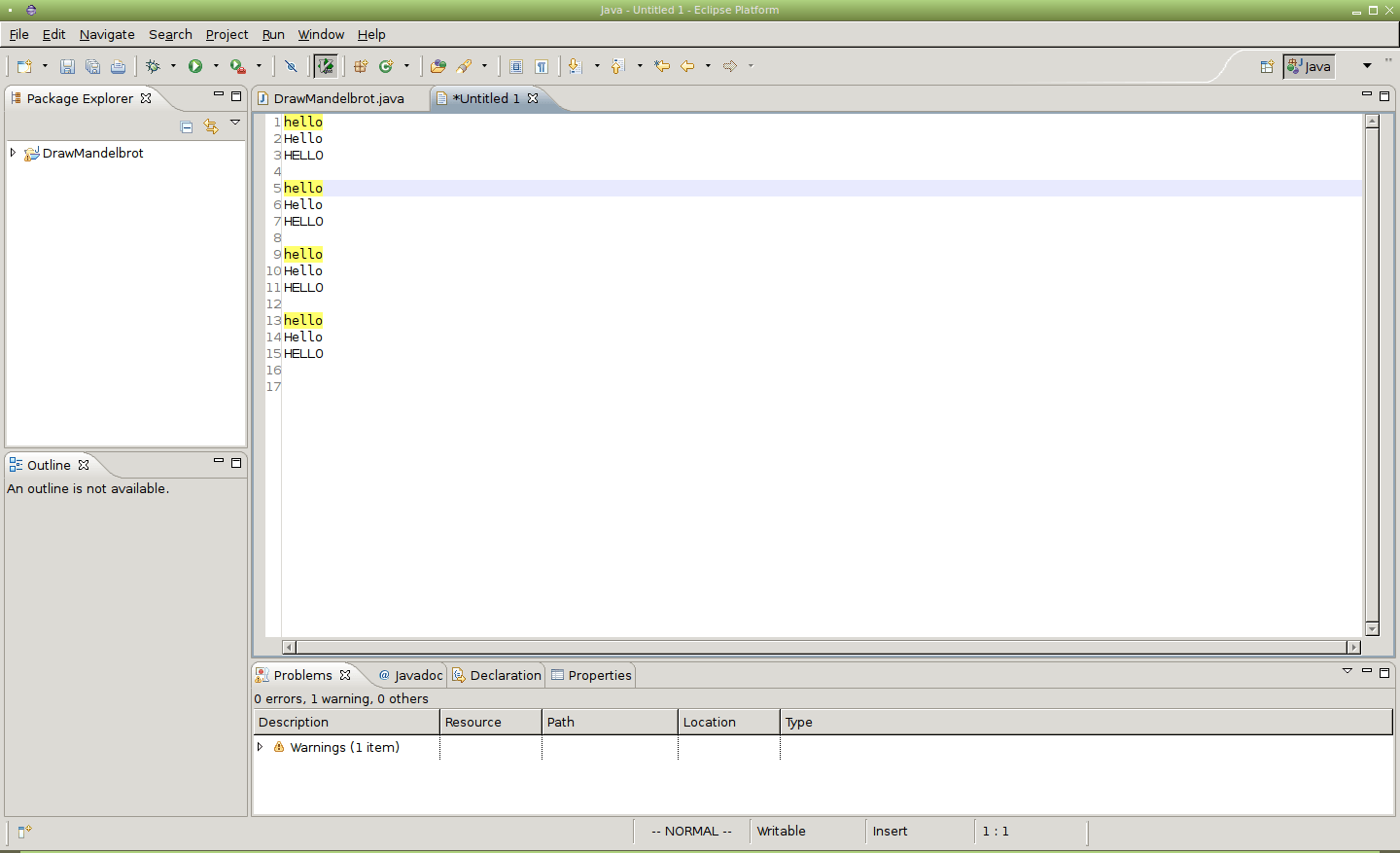
Obrázek 14: Vyhledání řetězce „hello“, nastavené volby noignorecase a nosmartcase.

Obrázek 15: Vyhledání řetězce „Hello“, nastavené volby noignorecase a nosmartcase.

Obrázek 16: Vyhledání řetězce „Hello“, nastavené volby ignorecase a nosmartcase.

Obrázek 17: Vyhledání řetězce „Hello“, nastavené volby ignorecase a smartcase.

Obrázek 18: Vyhledání řetězce „hello“, nastavené volby ignorecase a smartcase.
6. Použití regulárních výrazů při vyhledávání
Vzhledem k tomu, že vyhledávaný vzorek může obsahovat regulární výraz, otevírají se zde uživatelům přídavného modulu Vrapper velmi široké možnosti. Díky použití regulárních výrazů je totiž možné specifikovat jak různé skupiny znaků (čísla, alfanumerické znaky atd.), tak i přesně stanovit, kolikrát se tyto znaky ve vyhledávaném textu mohou objevit.
V regulárních výrazech je možné při vyhledávání v textu použít několik skupin znaků se speciálním významem. Následující znaky reprezentují začátek a konec řádku nebo slova, takže je možné například jednoduše nalézt slovo nacházející se na začátku řádku apod.:
| Znak(y) v regexpu | Význam |
|---|---|
| ^ | začátek řádku |
| $ | konec řádku |
| \< | začátek slova |
| \> | konec slova |
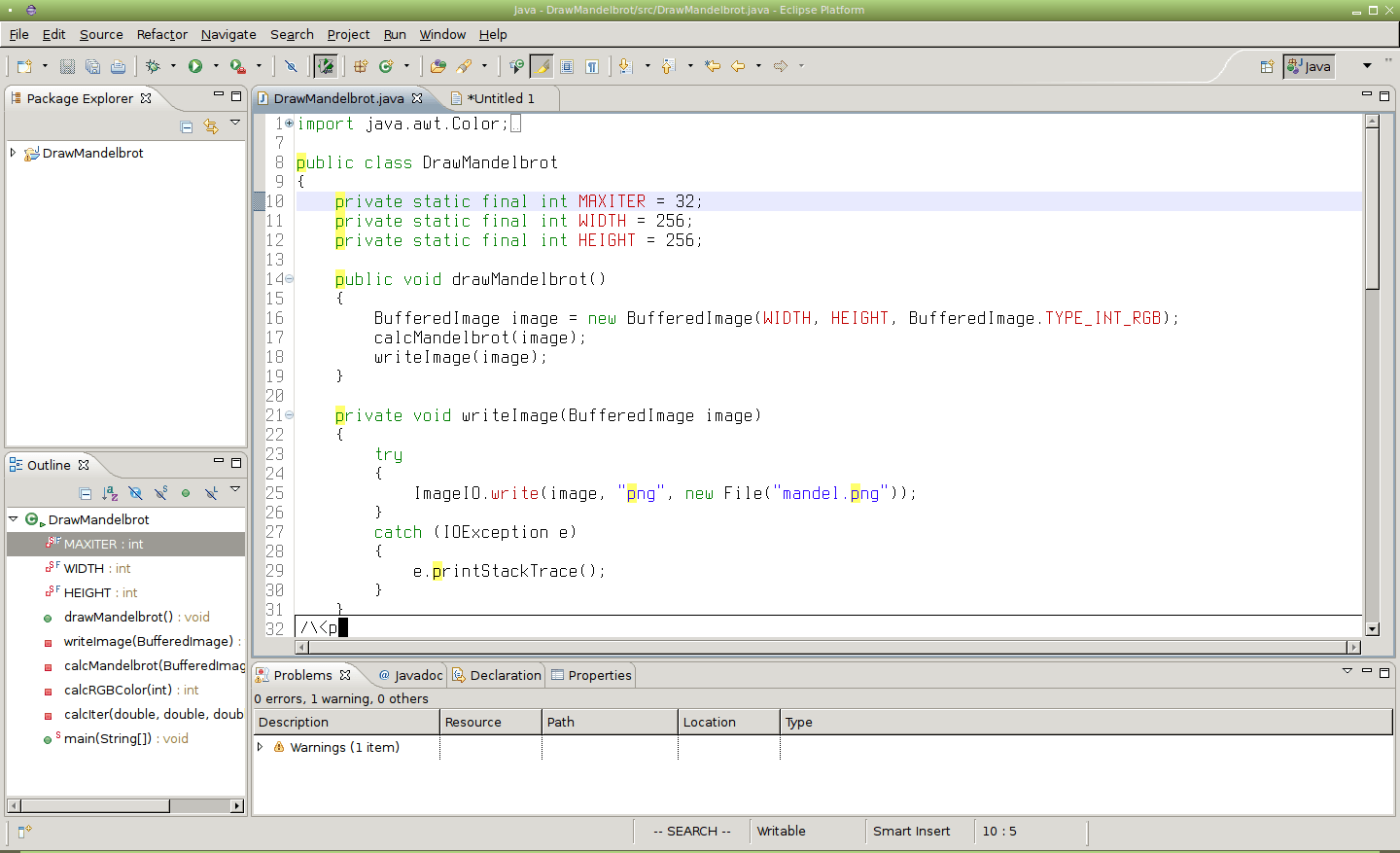
Obrázek 19: Vyhledání slova začínajícího znakem „p“. Příkaz pro vyhledání tohoto slova (či slov) vypadá následovně: /\<p
Specifikovat je možné i různé speciální znaky, které se mohou ve zdrojových kódech či jiných textových souborech v některých případech vyskytovat (pravděpodobně nejčastěji se setkáte se znakem Tab):
| Znak(y) v regexpu | Význam |
|---|---|
| \e | Esc |
| \t | Tab |
| \r | CR |
| \b | Backspace |
| \n | Konec řádku |
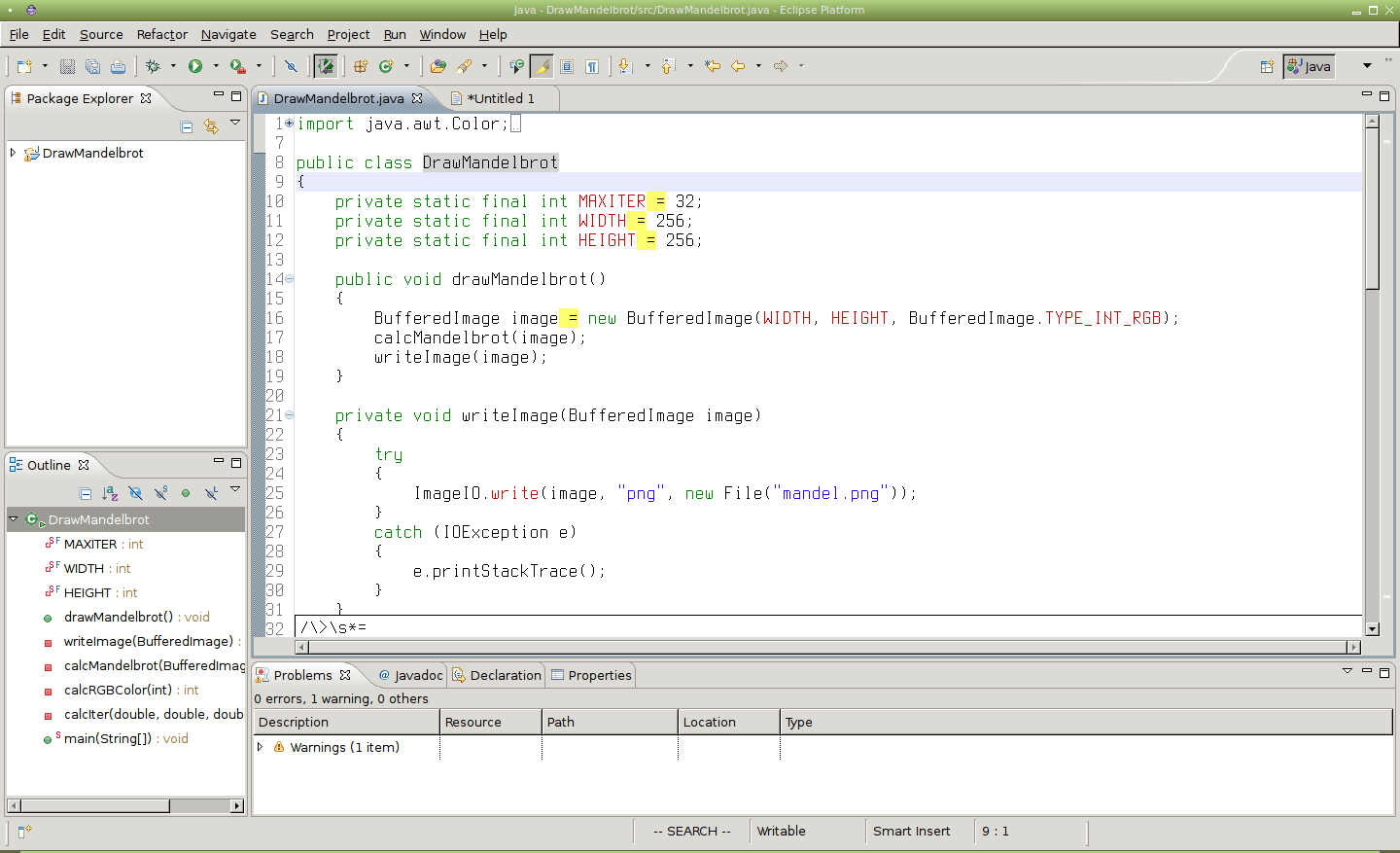
Obrázek 20: Vyhledání znaku „=“, který je uveden za koncem slova. Mezi koncem slova a znakem „=“ se může nacházet libovolné množství takzvaných bílých znaků (mezer, Tabů). Příkaz pro vyhledání vypadá následovně: /\>\s*=
Namísto jediného znaku se může v regulárním výrazu použít i množina znaků definovaná buď výčtem nebo rozsahem. Podívejme se na několik příkladů:
| Znak(y) v regexpu | Význam |
|---|---|
| [rgb] | jeden za znaků „r“, „g“ či „b“ |
| [rgb01] | jeden za znaků „r“, „g“, „b“, „0“ či „1“ |
| [a-z] | jeden ze znaků malé abecedy |
| [a-zA-Z] | jeden ze znaků malé či velké abecedy |
| [0-9] | libovolná číslice |
| [^a-z] | negace, vše kromě znaku malé abecedy |
| [^0-9] | negace, vše kromě číslice |
V regulárních výrazech je možné použít i takzvané třídy znaků, zejména:
| Znak(y) v regexpu | Význam |
|---|---|
| . | libovolný znak v textu |
| \s | tzv. bílý znak (mezera, Tab) |
| \S | opak předchozího, tj. vše kromě bílých znaků |
| \d | decimální číslice |
| \D | opak předchozího (jakýkoli znak mimo číslice) |
| \w | znaky A-Z, a-z a podtržítko |
| \W | opak předchozího |
Poznámka: některé třídy znaků, které bylo možné použít v originálním textovém editoru Vimu, nejsou ve Vrapperu (alespoň prozatím, tj. v jeho aktuální verzi) podporovány.
U jednotlivých znaků či jejich skupin lze v případě potřeby specifikovat i počet opakování:
| Znak(y) v regexpu | Význam |
|---|---|
| * | nula nebo více opakování |
| + | jedno nebo více opakování |
| \{n,m} | od n do m opakování |
| \{n,} | od n opakování |
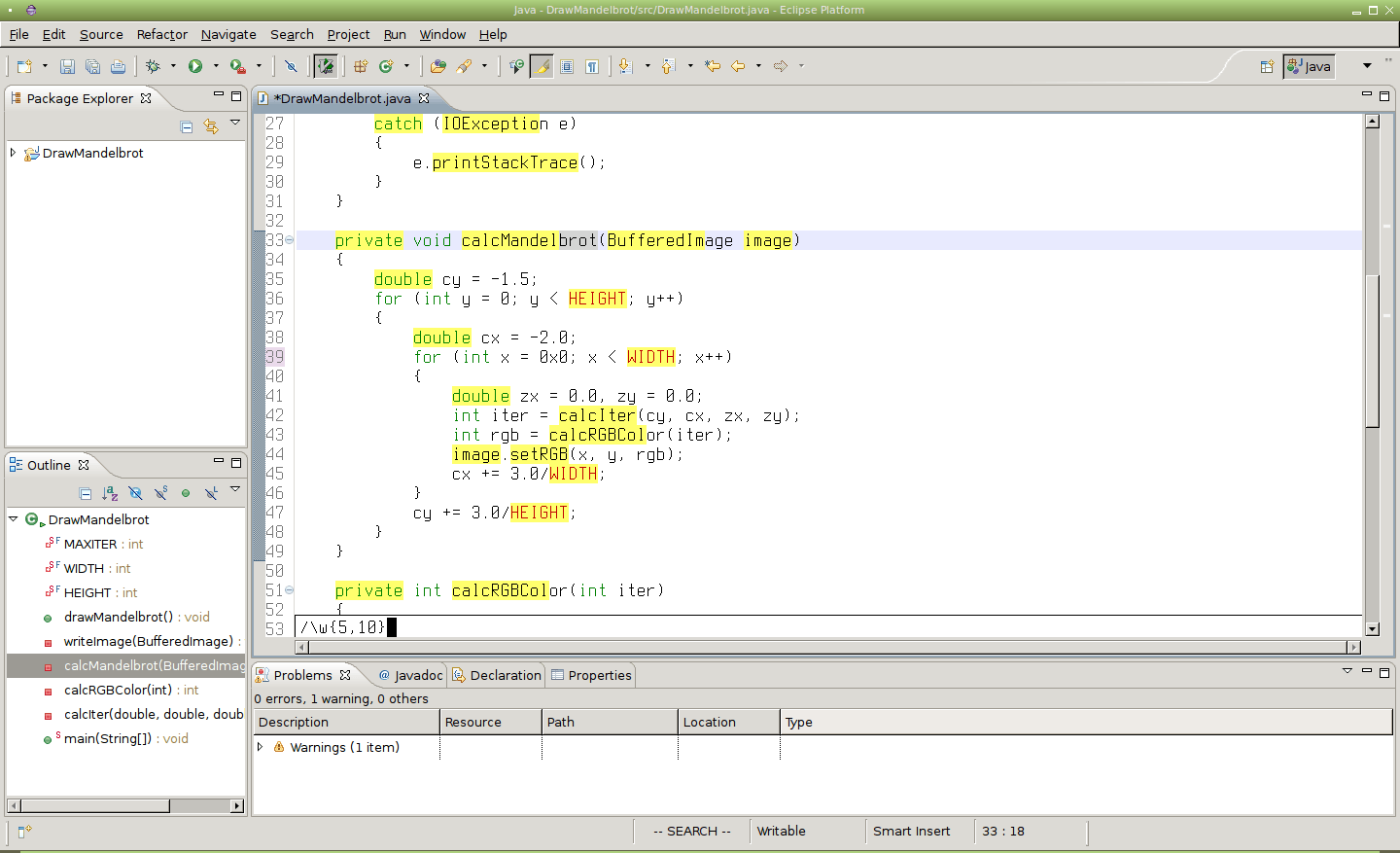
Obrázek 21: Vyhledání všech slov s délkou od pěti do deseti znaků. Příkaz pro vyhledání vypadá následovně: /\w{5,10}
7. Příkaz pro vyhledání s nahrazením (substitute)
Velmi užitečným příkazem, s nímž se můžeme setkat jak v textovém editoru Vim, tak i ve Vrapperu, je příkaz pojmenovaný substitute. Jak již název tohoto příkazu naznačuje, používá se ve chvíli, kdy je nutné ve zdrojovém kódu provést náhradu nějakého textového vzorku za jiný text. Ve skutečnosti jsou však možnosti příkazu substitute mnohem větší, než je tomu u klasických příkazů typu „Najdi a nahraď“, které mohou mnozí uživatelé znát z dalších typů textových editorů, a to zejména z toho důvodu, že v substitute lze použít regulární výrazy a navíc je možné ovlivnit, se kterou částí zdrojového kódu má příkaz substitute pracovat. Úplný tvar tohoto příkazu vypadá následovně:
:[rozsah]s/vyhledávaný_vzorek/nahrazující_text/[přepínače]
popř:
:[rozsah]substitute/vyhledávaný_vzorek/nahrazující_text/[přepínače]
Přičemž [rozsah] a [přepínače] nemusí být uvedeny, takže v nejjednodušším případě vypadá příkaz substitute takto (v této podobě se nalezne a nahradí text pouze na aktuálním řádku):
:s/vyhledávaný_vzorek/nahrazující_text
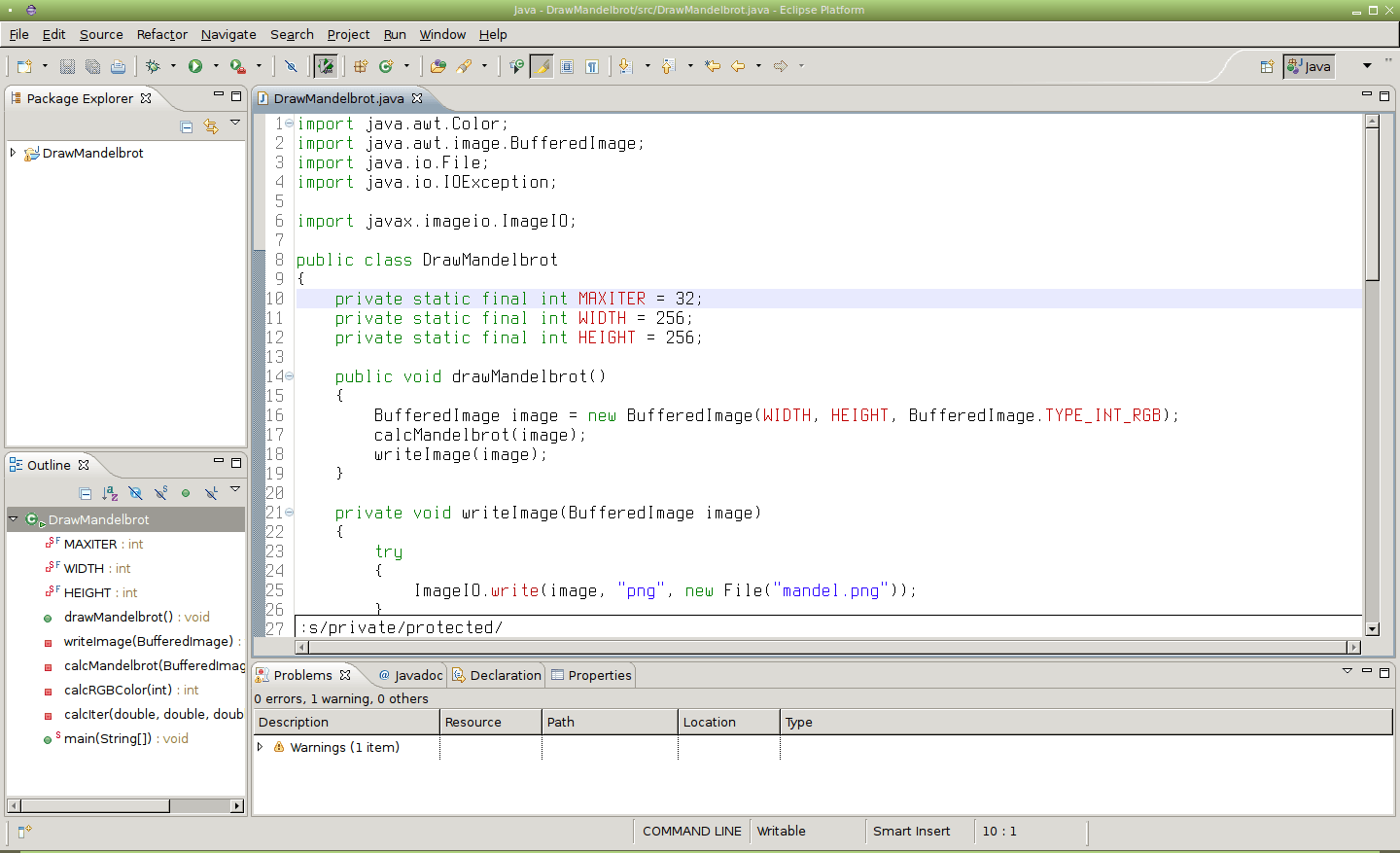
Obrázek 22: Nahrazení slova „private“ za slovo „protected“, ovšem pouze na aktuálním řádku.
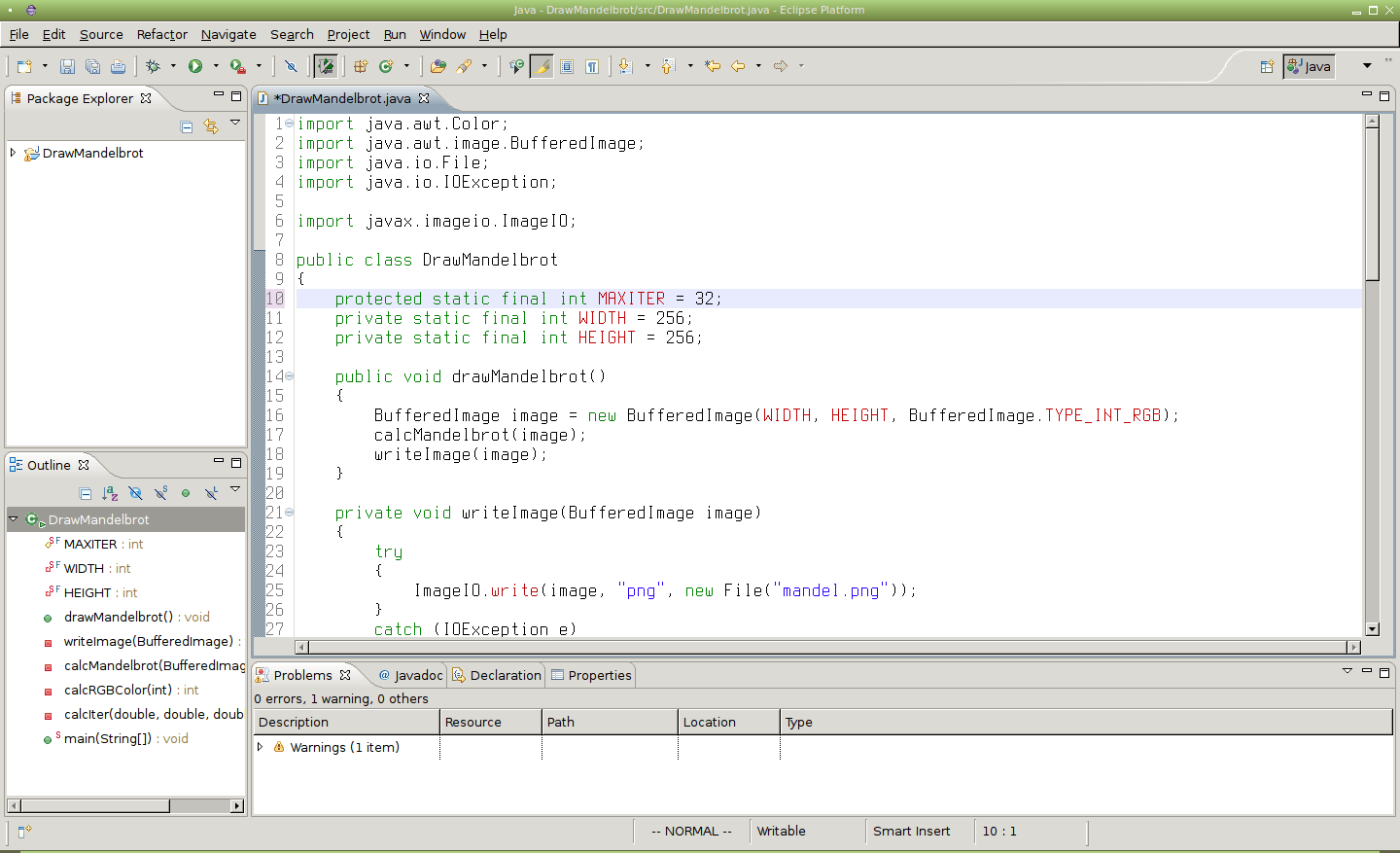
Obrázek 23: Výsledek zavolání příkazu :s/private/protected/
8. Specifikace rozsahu nahrazování
V mnoha případech však nechceme nahrazovat pouze text, který se nachází na jednom řádku – potom je nutné specifikovat rozsah. Pokud se má nahrazení provést v celém zdrojovém kódu (velmi častý požadavek), může se použít znak % způsobem, jaký je naznačen na následující dvojici screenshotů:
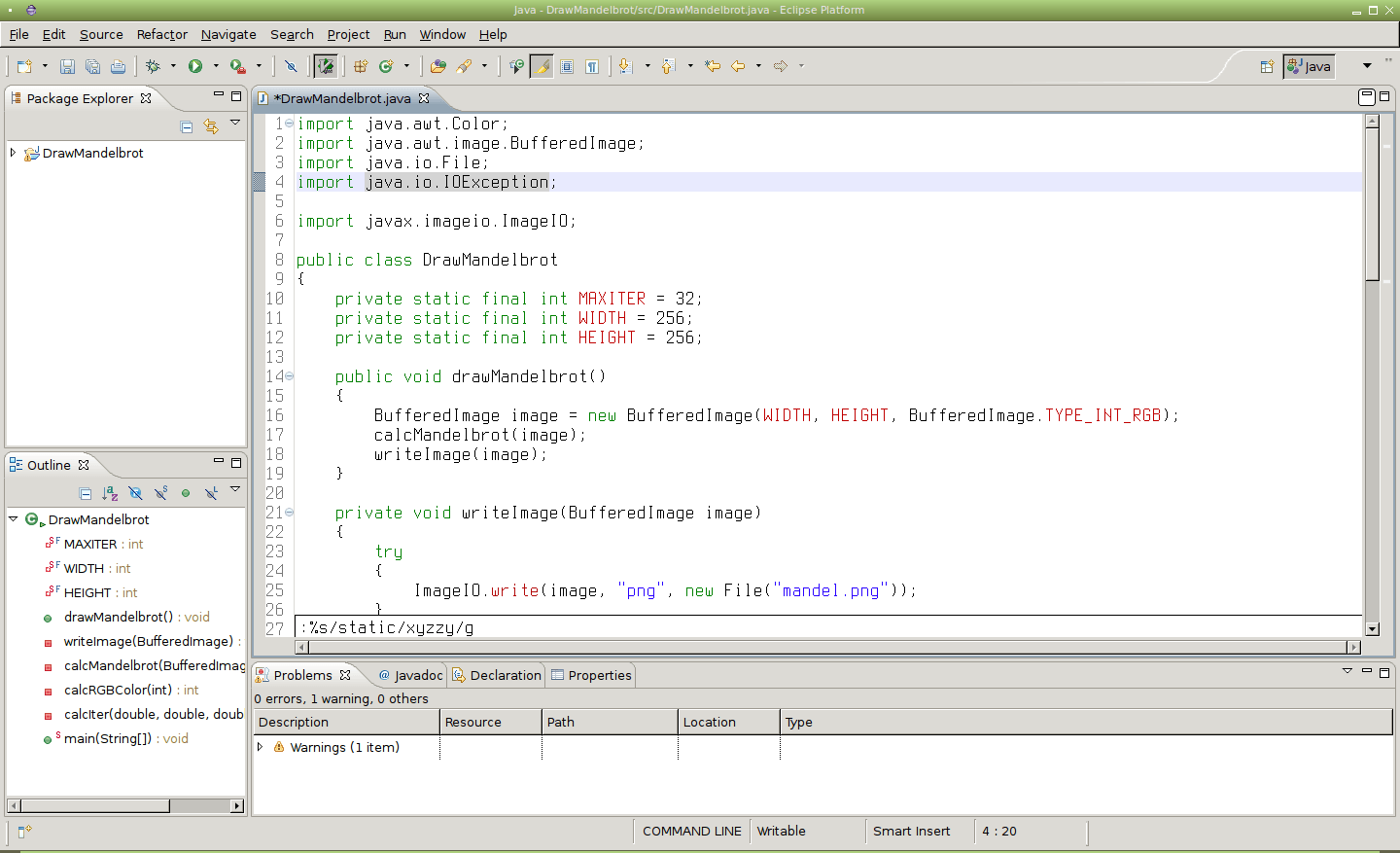
Obrázek 24: Nahrazení všech slov „static“ za „xyzzy“.
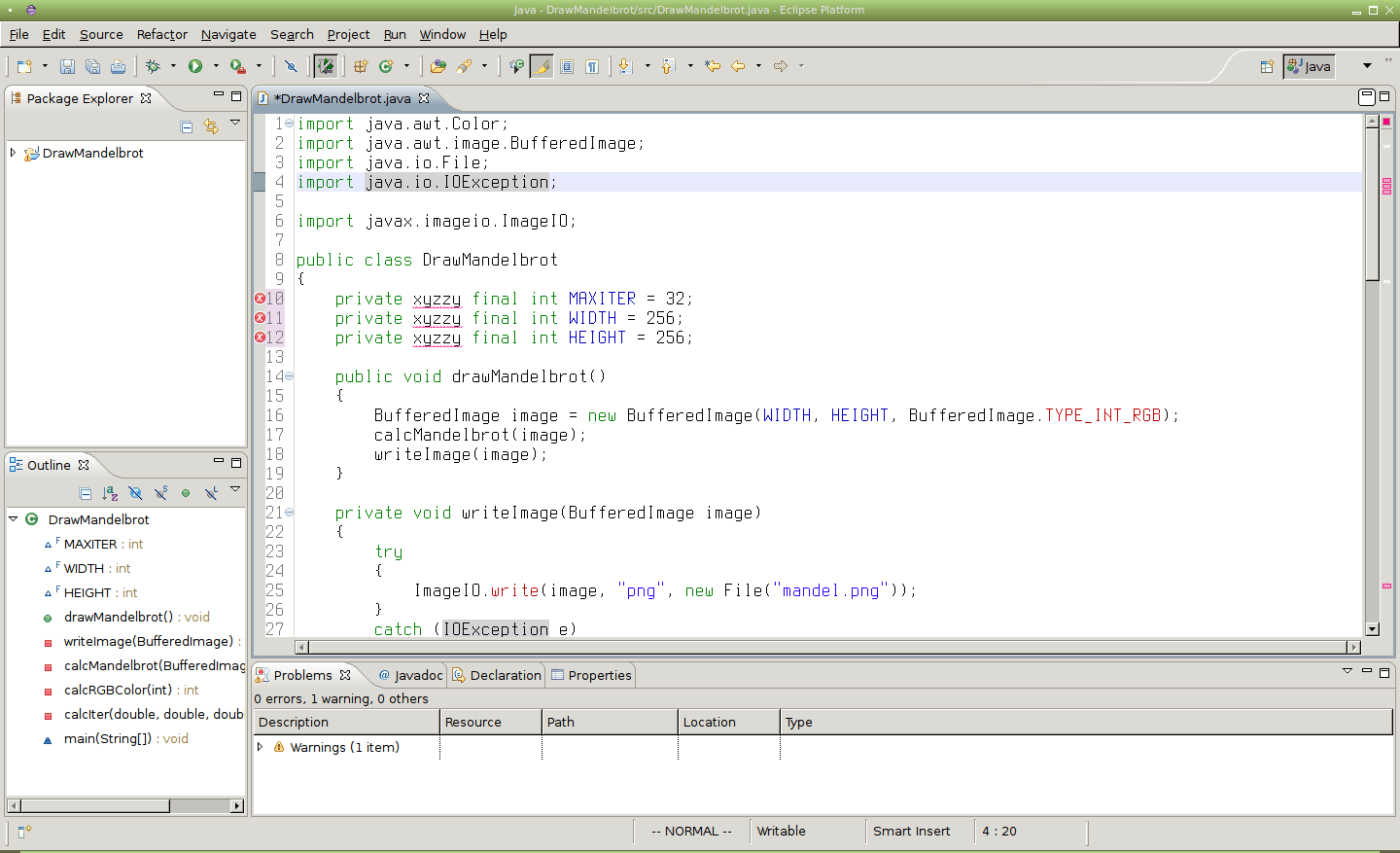
Obrázek 25: Výsledek použití příkazu :%s/static/xyzzy/g (g znamená globální nahrazení, viz též další kapitolu s podrobnějším popisem).
Taktéž je možné rozsah specifikovat pomocí dvou čísel odpovídajících číslům řádků. Opět se podívejme na dvojici screenshotů, kde je tato možnost použita:
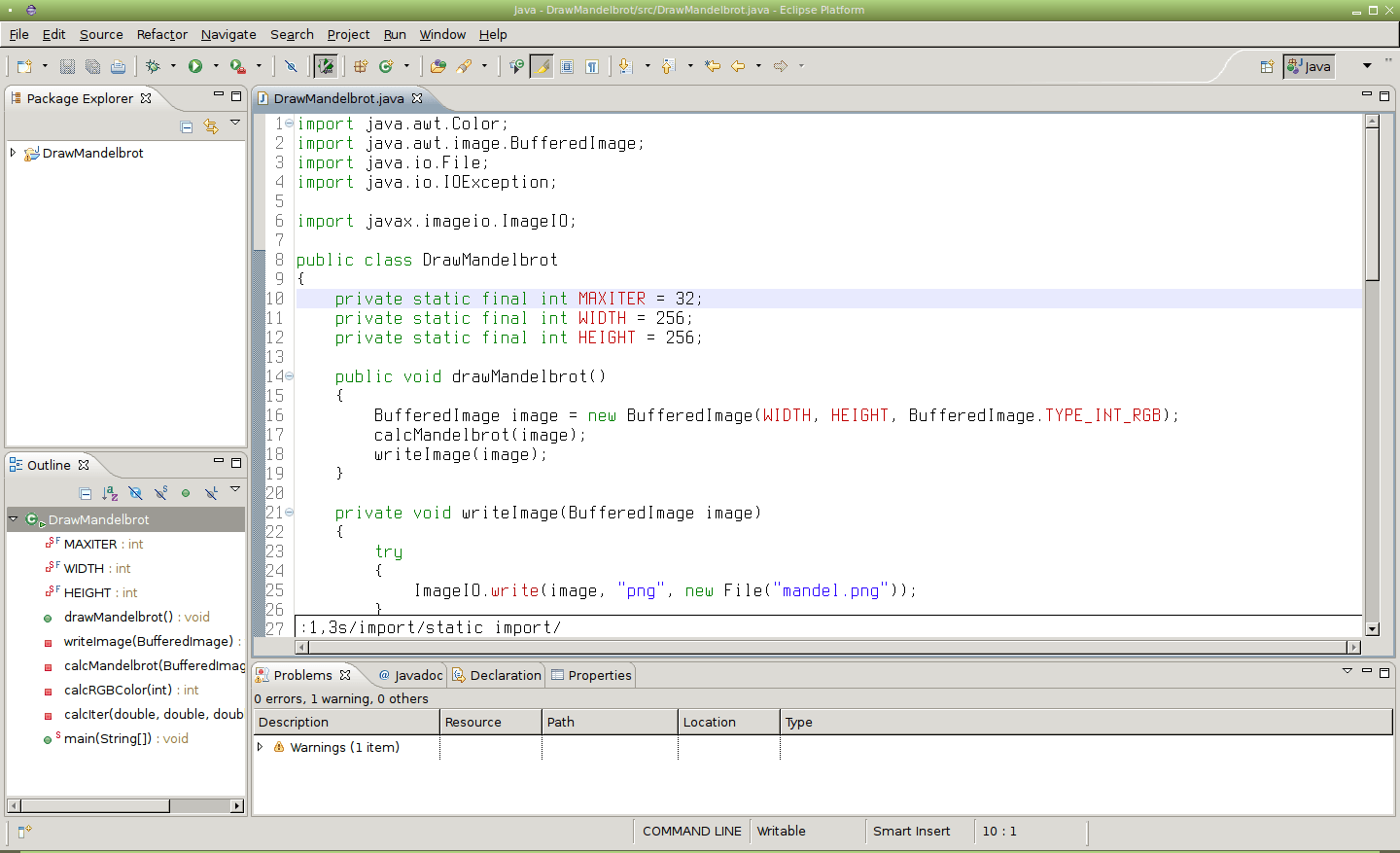
Obrázek 26: Nahrazení všech slov „import“ za „static import“, ovšem pouze na prvních třech řádcích.
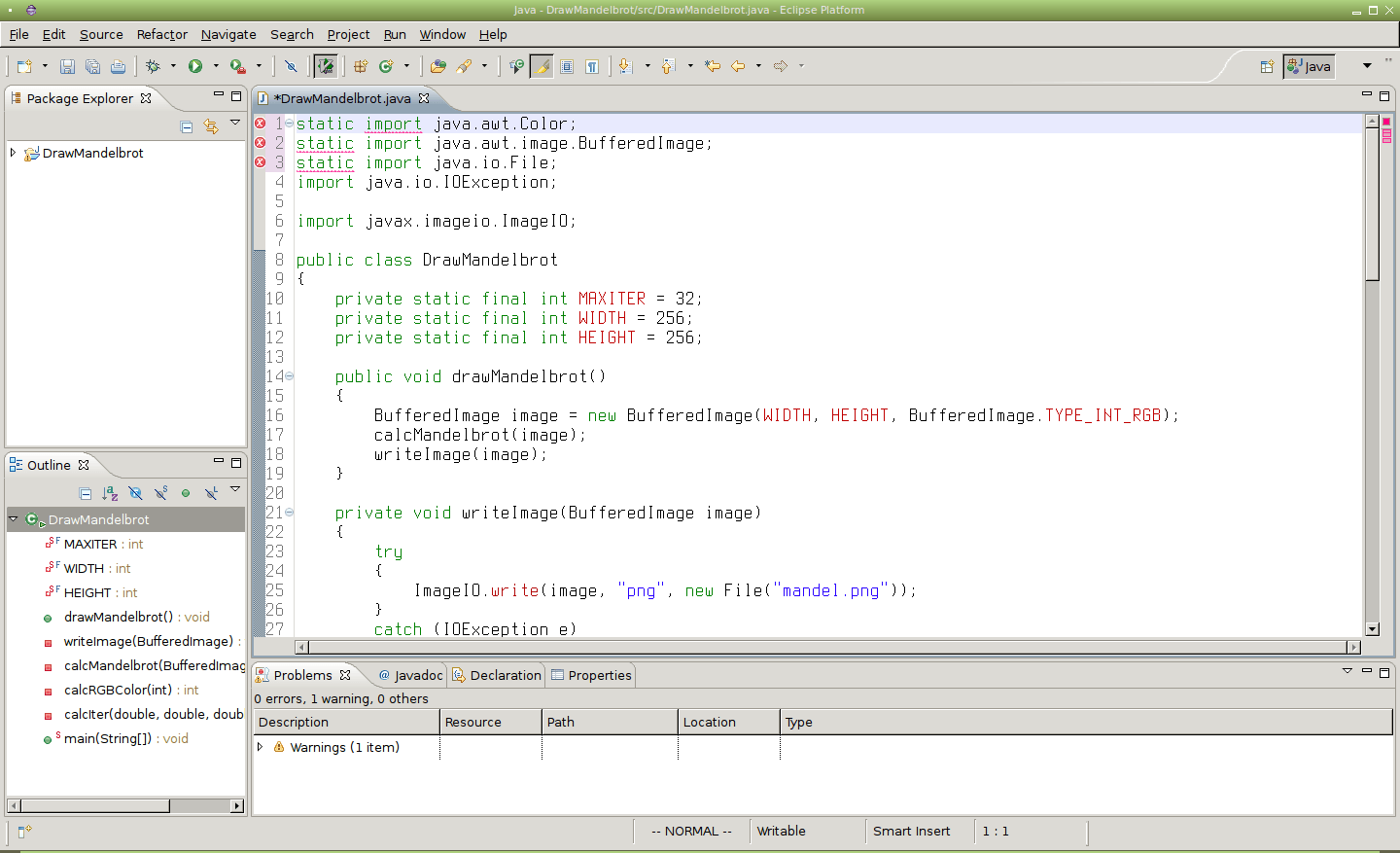
Obrázek 27: Výsledek použití příkazu :1,3s/import/static import
Alternativně je možné text vybrat do bloku (klávesa v či V pro vstup do vizuálního režimu), což automaticky povede k vložení znaků pro začátek a konec vizuálního označení v příkazu substitute. V praxi to znamená, že se nahrazování bude týkat pouze označeného textu:
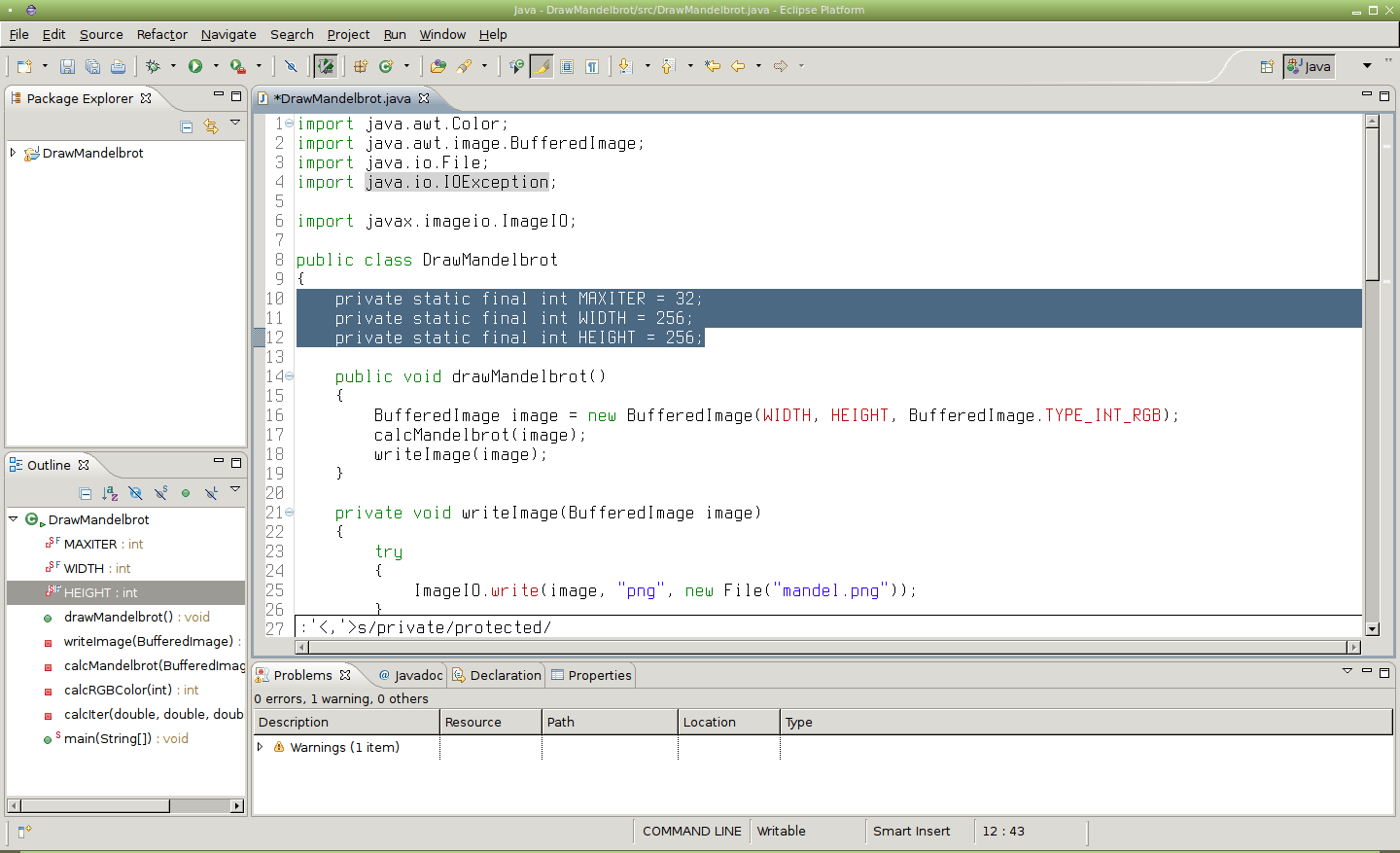
Obrázek 28: Nahrazení všech slov „private“ za „protected“, ovšem pouze v označeném bloku textu.
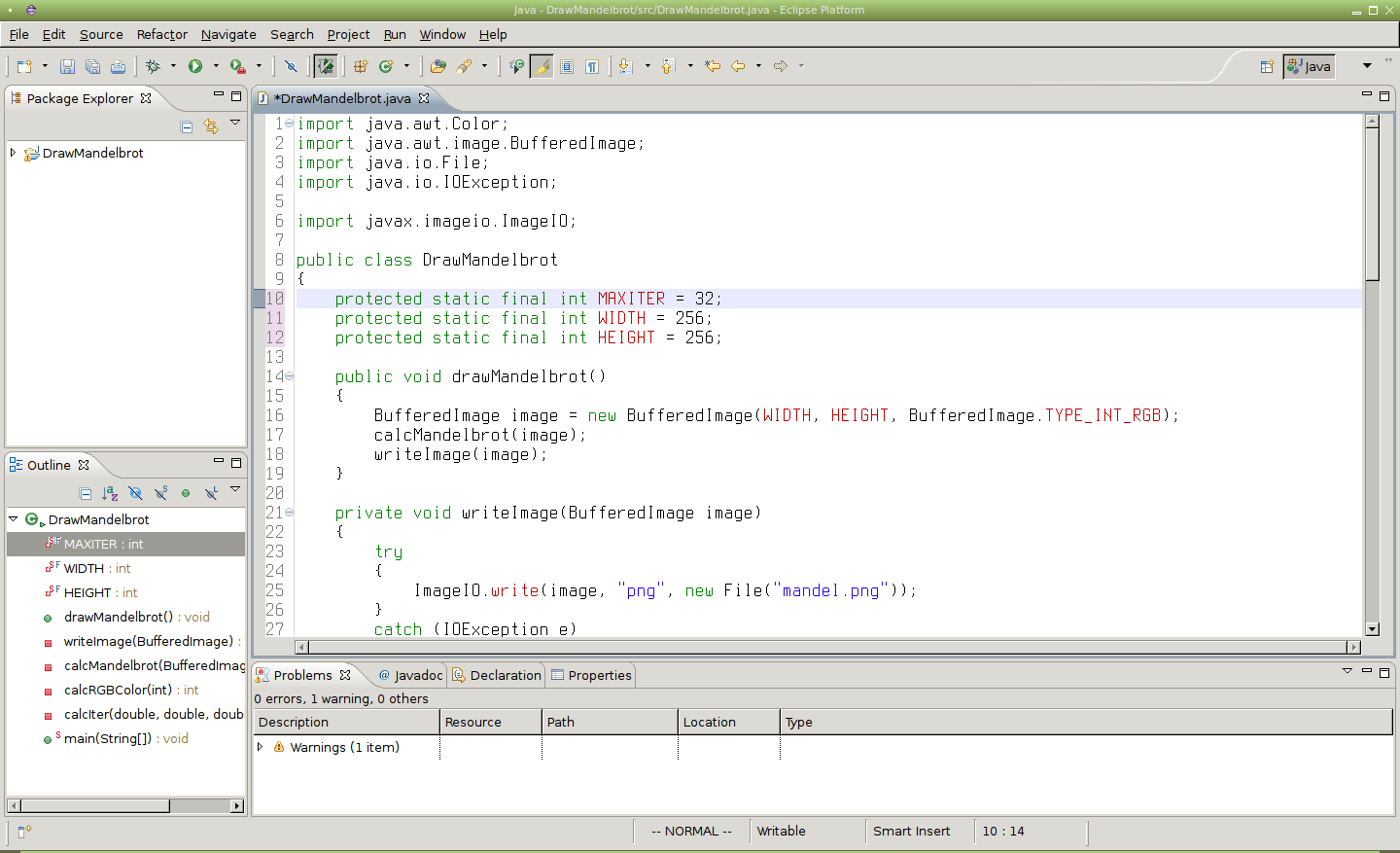
Obrázek 29: Výsledek použití příkazu :'<,'>s/private/protected/ (začátek příkazu je doplněn automaticky, protože editor rozpozná režim vizuálního výběru textu).
Ve skutečnosti není zapotřebí používat v příkazu substitute pouze lomítka, ale je možné zvolit i jiný znak, například pomlčku:
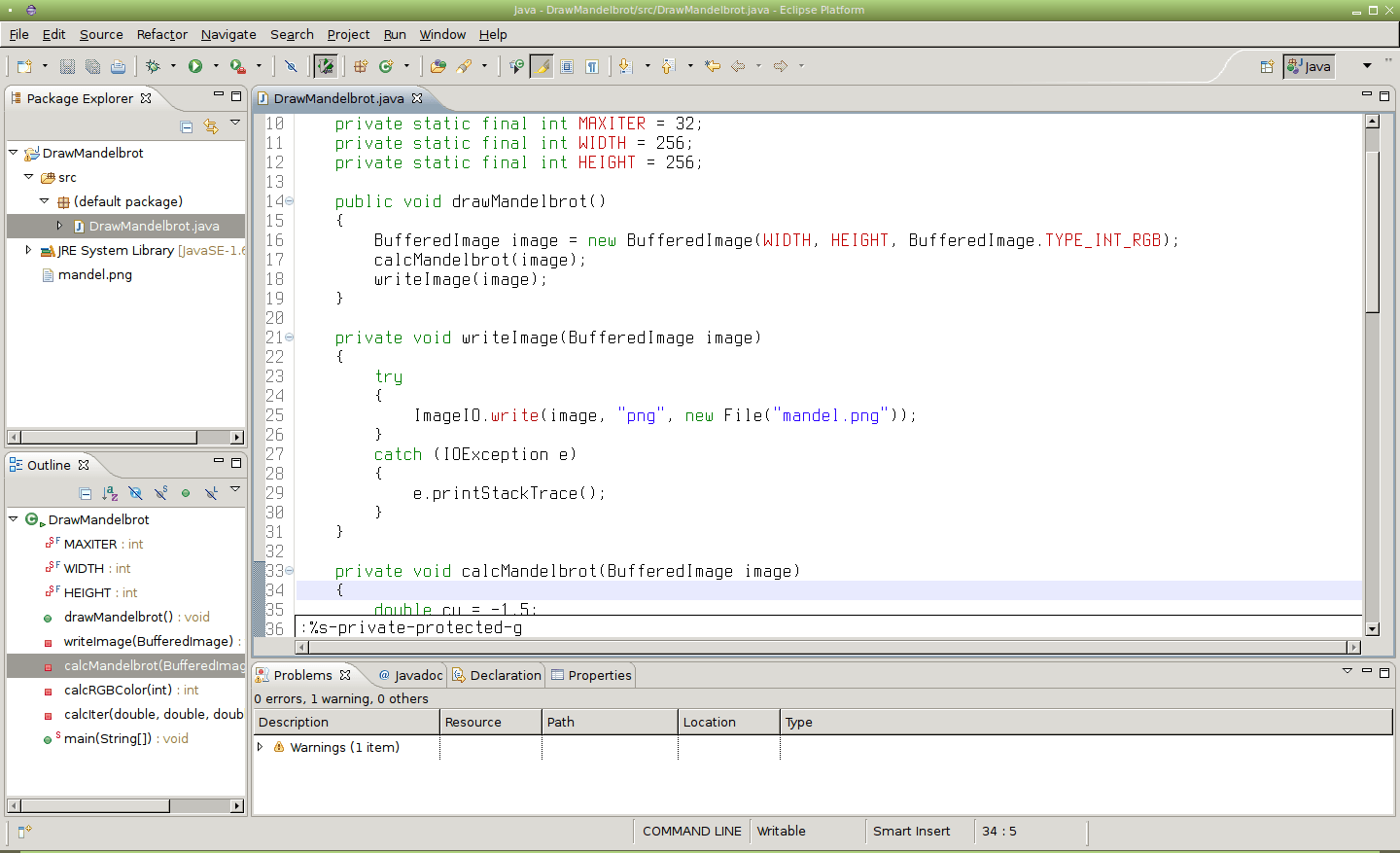
Obrázek 30: Použití pomlčky namísto lomítka v příkazu substitute.
9. Rozsah nahrazování zadaný pomocí vyhledávacích příkazů
Poslední možností, jak v příkazu substitute určit tu část textu, v níž se má provádět nahrazování, spočívá ve využití vyhledávacích příkazů. V tomto případě má příkaz substitute tvar:
:/vzorek1/,/vzorek2/s/vyhledávaný_vzorek/nahrazující_text :?vzorek1?,/vzorek2/s/vyhledávaný_vzorek/nahrazující_text :?vzorek1?,?vzorek2?s/vyhledávaný_vzorek/nahrazující_text
Zápis /vzorek/ znamená vyhledávání vzorku směrem vpřed (ke konci souboru), zatímco zápis ?vzorek? vyhledávání od pozice kurzoru směrem k začátku souboru. Ukázka tohoto nejsložitějšího tvaru příkazu substitute je na screenshotu číslo 31:
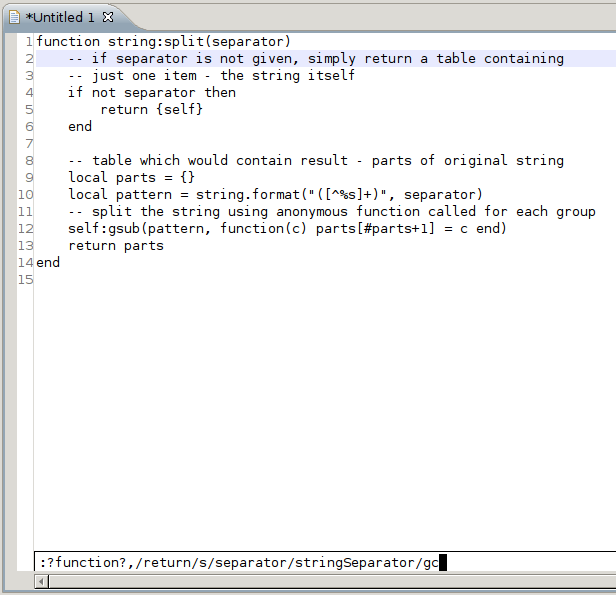
Obrázek 31: Nahrazení slova „separator“ za „stringSeparator“, ovšem jen v textu, který se nachází na řádcích se slovy „function“ a „return“.
10. Význam některých přepínačů příkazu substitute
Poslední nepovinnou položkou příkazu substitute jsou příznaky, které se v případě potřeby mohou zadat za poslední rozdělovací znak. My jsme prozatím v naších demonstračních příkladech používali pro oddělení jednotlivých částí příkazu substitute lomítko, může se však jednat i o jiný znak, typicky o pomlčku. Příznaky ovlivňují způsob vyhledávání a taktéž to, zda se mají nahradit všechny výskyty vzorku na jednom řádku či zda se naopak má nahradit pouze první nalezený výskyt (což je výchozí chování příkazu substitute). Některé příznaky je možné kombinovat, u dalších to nedává smysl. Pokud se příznaky kombinují, zapisují se přímo za sebe bez jakýchkoli oddělovačů, například:
:%s/foo/bar/gc :%s/foo/bar/gci :%s/foo/bar/igc :%s-foo-bar-Ig :%s:foo:bar:gc
Význam jednotlivých příznaků příkazu substitute je uveden v následující tabulce:
| # | Příznak | Význam |
|---|---|---|
| 1 | g | nahradí se všechny výskyty vzorku na řádku (ve výchozím stavu se nahradí jen první výskyt) |
| 2 | c | před nahrazením se plugin zeptá, zda se náhrada má skutečně provést |
| 3 | i | ignorování velikosti písmen při vyhledávání |
| 4 | I | zákaz ignorování velikosti písmen při vyhledávání |
| 5 | & | použijí se příznaky posledního příkazu substitute |
Opět se podívejme na demonstrační příklady:
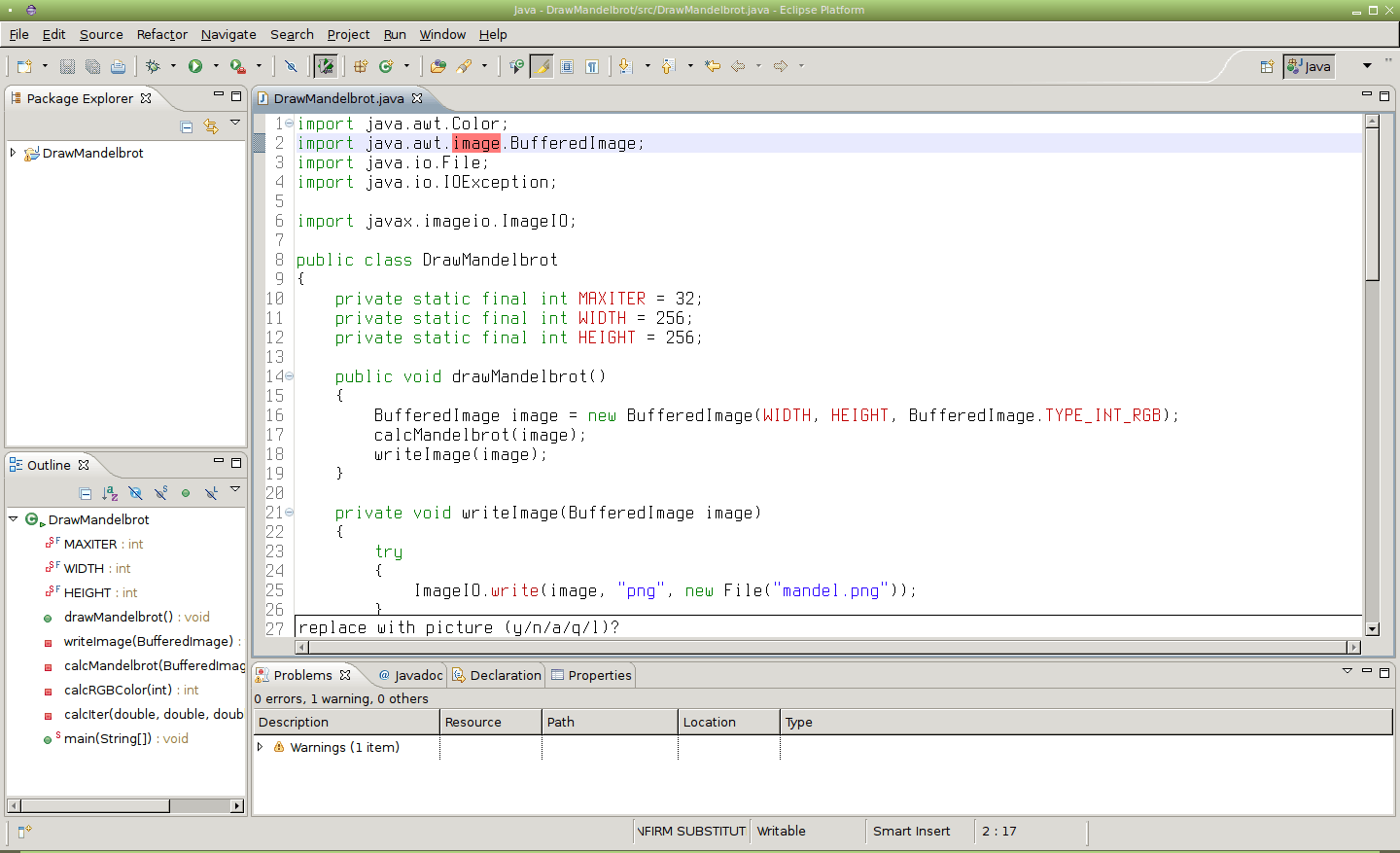
Obrázek 32: Po specifikaci příznaku c se bude plugin před každým nahrazováním ptát, zda se má nahrazení provést (y), neprovést (n), provést všechna další nahrazení (a) nebo se má ukončit (q).
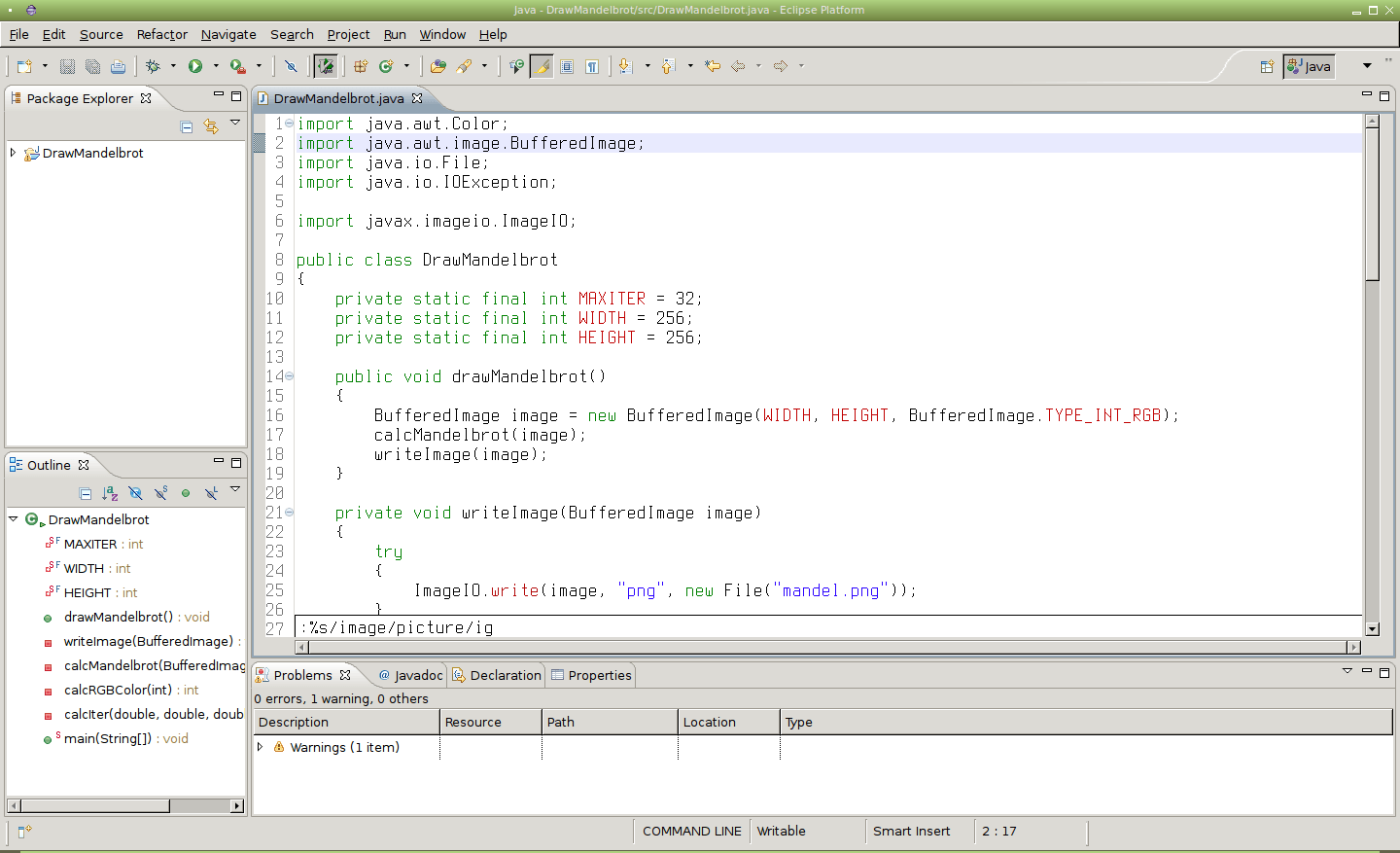
Obrázek 33: Globální nahrazení části slova „image“ za „picture“ s ignorováním velikosti písmen.
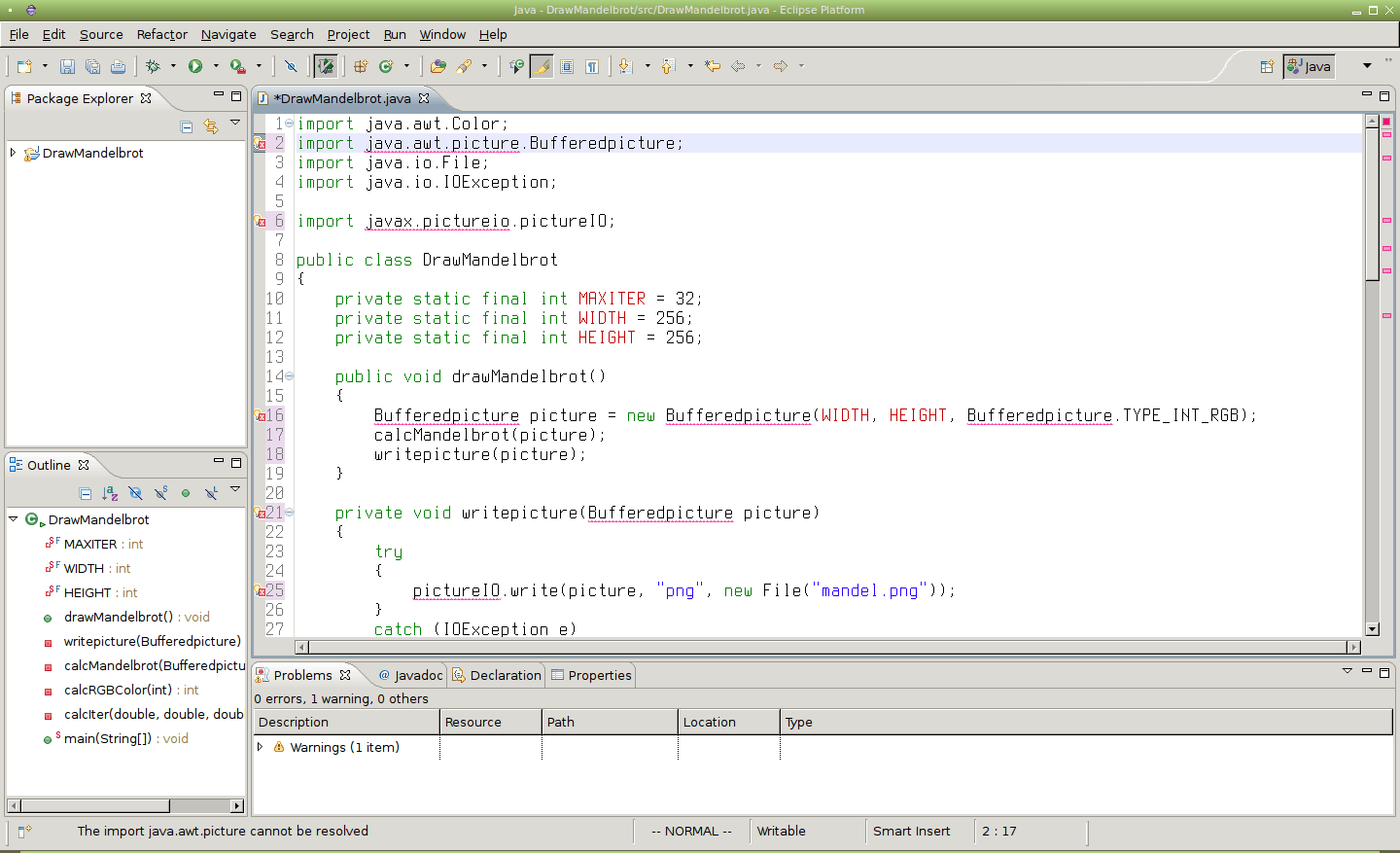
Obrázek 34: K nahrazení skutečně došlo, a to i v případě slova BufferedImage.
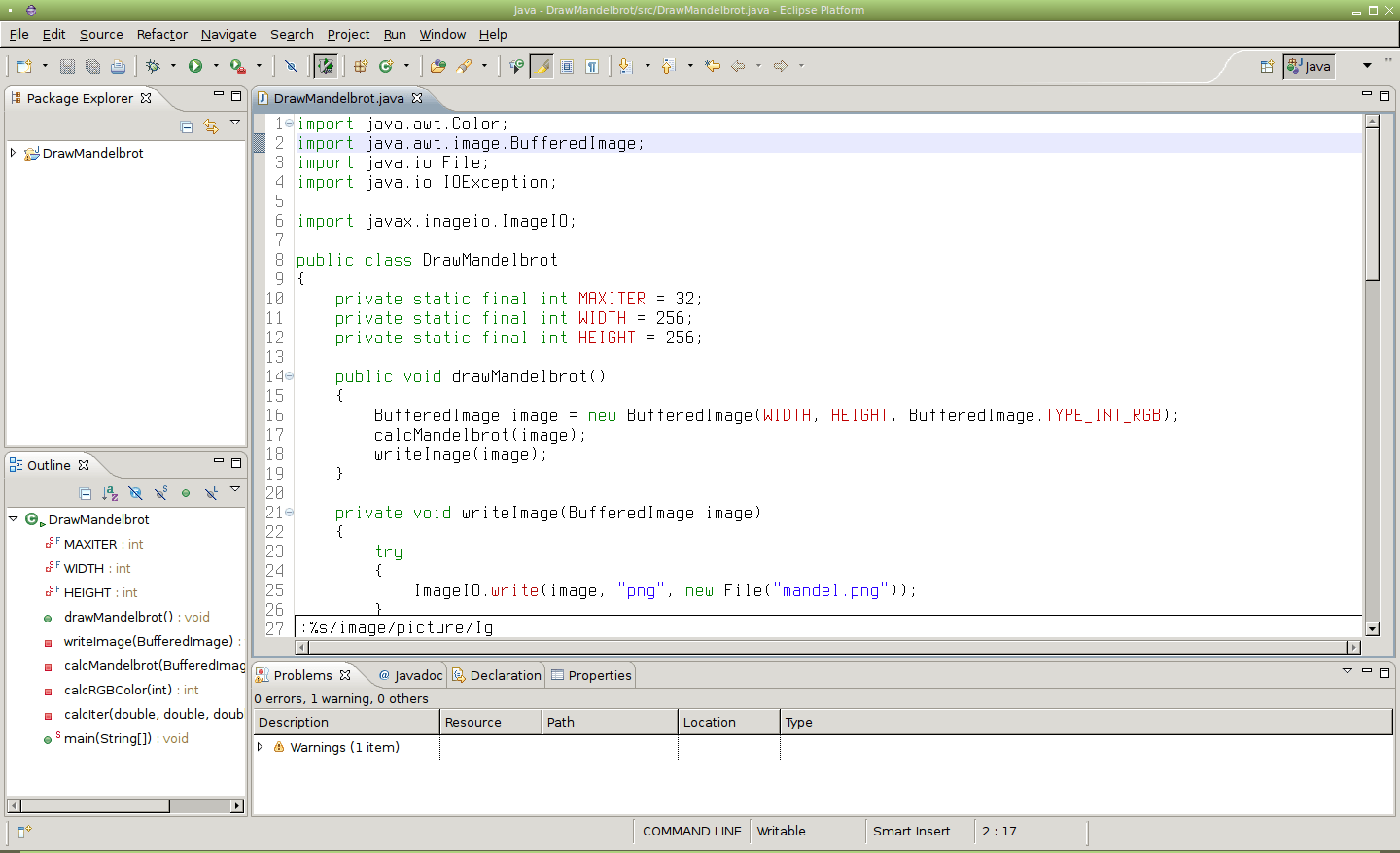
Obrázek 35: Globální nahrazení části slova „image“ za „picture“ bez ignorování velikosti písmen.
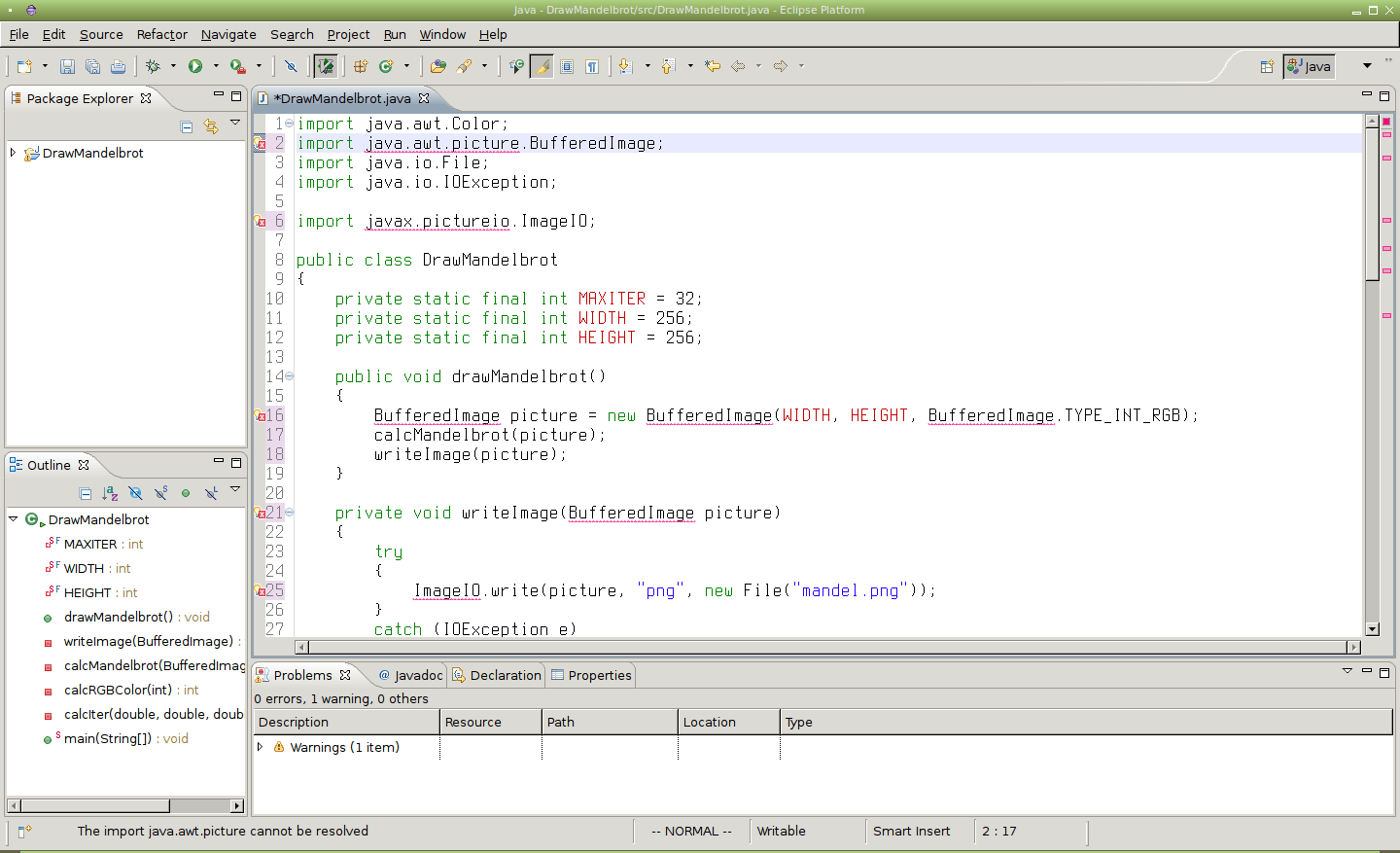
Obrázek 36: Došlo k nahrazení pouze slov „image“, nikoli „Image“.
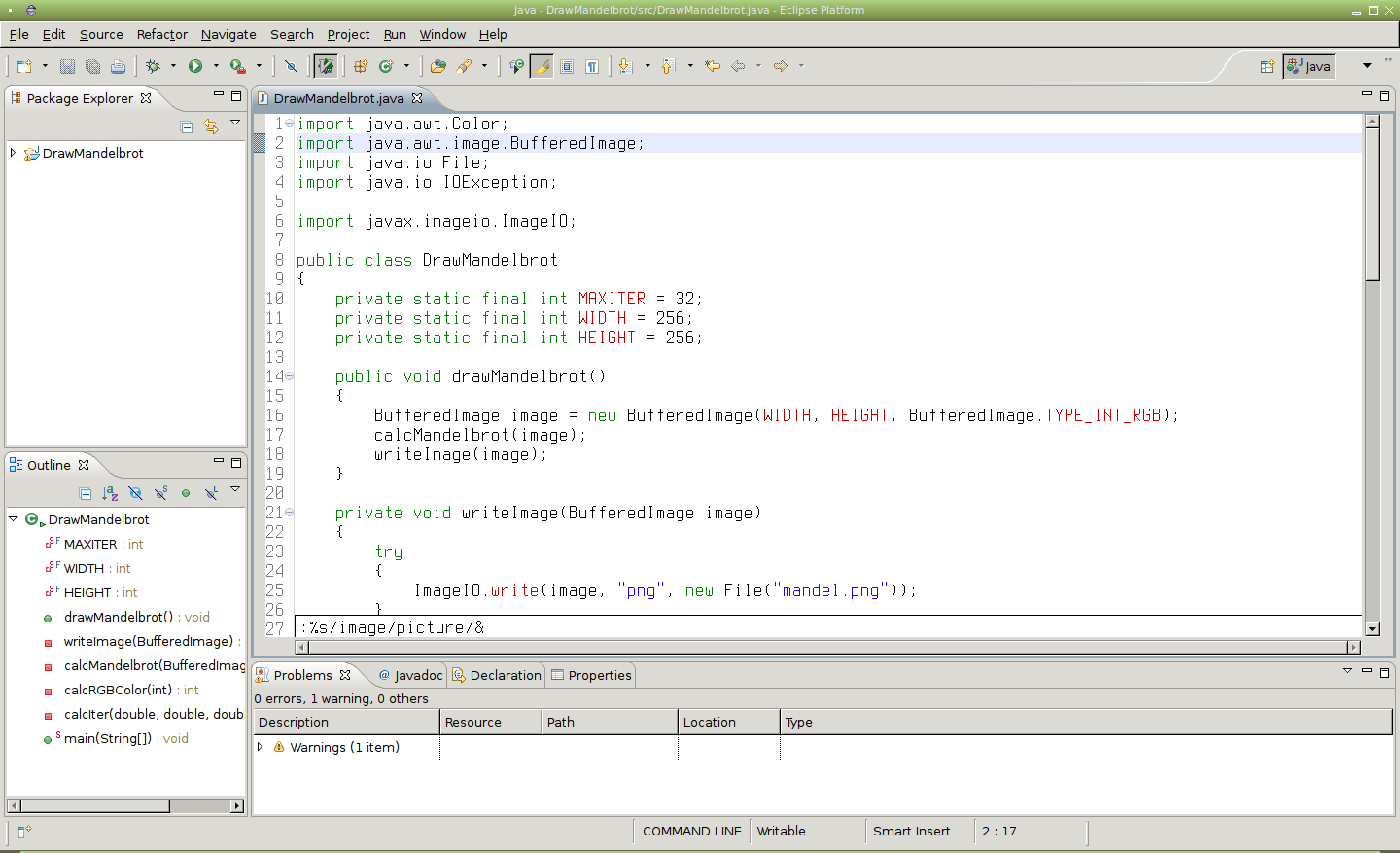
Obrázek 37: Příznak & znamená „použij parametry posledního příkazu substitute“.
11. Obsah třetí části článku
Ve třetí části článku o modulu Vrapper se zaměříme na popis mapování kláves příkazem :map a jeho variantami, Tento velmi užitečný příkaz je do značné míry totožný s funkcionalitou nabízenou samotným Vimem. Samostatnou kapitolu si zcela jistě zaslouží vysvětlení problematiky záznamu a následného použití maker, protože právě spojení makrosystému s možností použití Vimovských operátorů může vývojářům (či dalším uživatelům integrovaného vývojového prostředí Eclipse a pluginu Vrapper) ušetřit mnoho práce, a to nejenom při samotné editaci zdrojových kódů, ale například i při úpravě různých datových souborů, přípravě šablon HTML stránek apod.
